【Hadoop】伪分布式环境搭建
伪分布式环境搭建
前言
本案例基于阿里云CentOS7,仅作hadoop伪分布式搭建的过程命令及技巧总结
word笔记(下载)
Java环境搭建
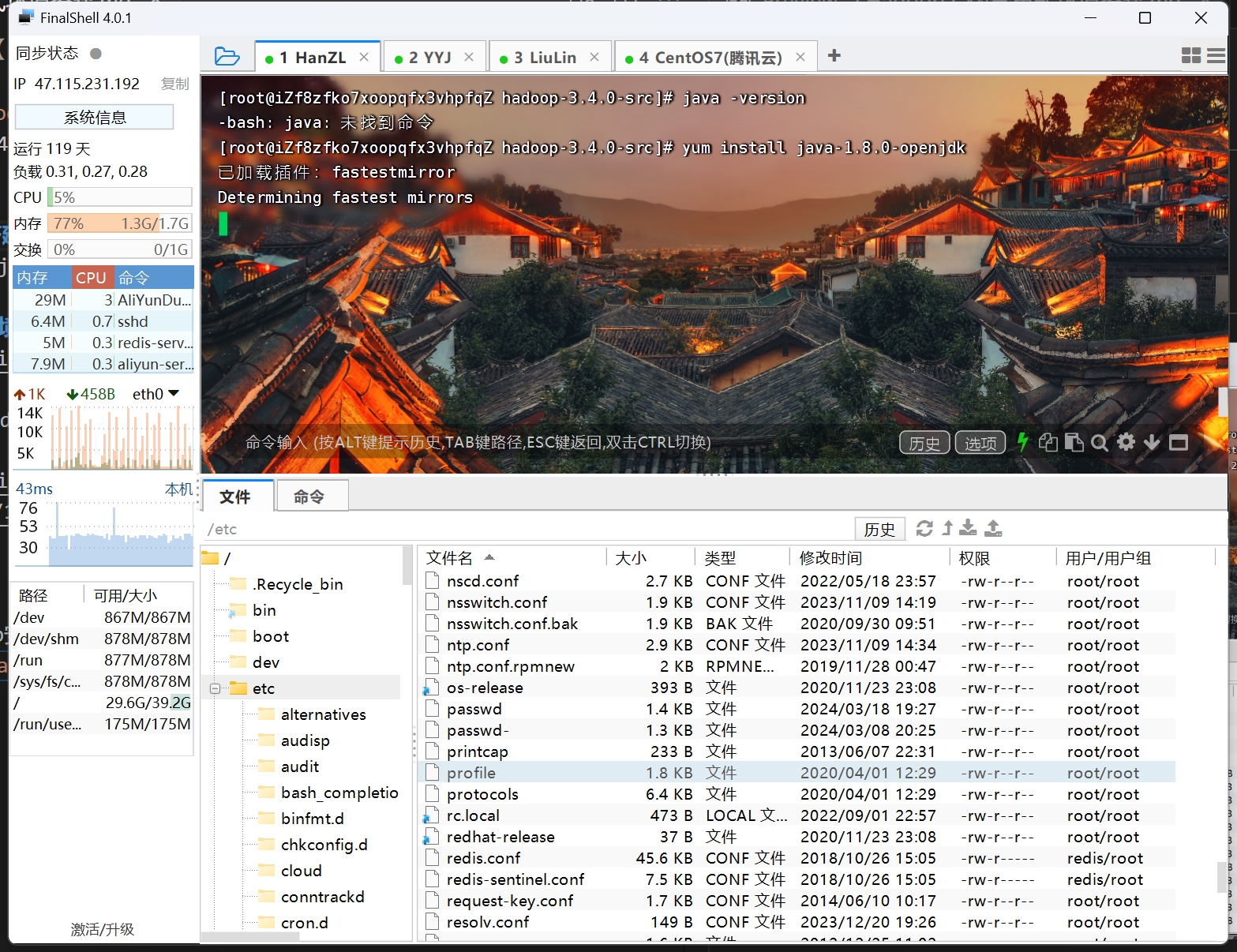
安装Java环境yum install java-1.8.0-openjdk-devel.x86_64
验证Java环境版本 java -version
查看Java安装地址 which java、alternatives --display java
- 解压hadoop安装包
安装包官网下载或者我的地址:
链接:https://124.221.138.245:32039/down/mD8mtZhm8DyP.gz
提取码:1234
解压hadoop安装包
tar -zxvf hadoop-2.10.2-src.tar.gz配置环境变量
vim /etc/profile
1 | export HADOOP_HOME = /home/Hanzl/app/hadoop-3.4.0-src |
验证环境变量echo $HADOOP_HOME
Hadoop 伪分布式环境搭建
Hadoop 配置文件很多,都位于 $HADOOP_HOME/etc/hadoop 下
1 |
|
Hadoop 的配置文件繁多,我们可采用最小配置(6 个配置文件),其余文件保留默认即可:
第 1 步:配置 hadoop-env.sh。


第 2 步:配置 core-site.xml。
1 | <property> |
配置 fs.defaultFS 指定 Hadoop 所使用的文件系统的 URI(统一资源标识符),示例中的 URI 包含协议(HDFS)、NameNode 的 IP 地址(或者机器名)和端口(9000)。
配置 hadoop.tmp.dir 指定 Hadoop 运行时产生的临时文件的存储目录。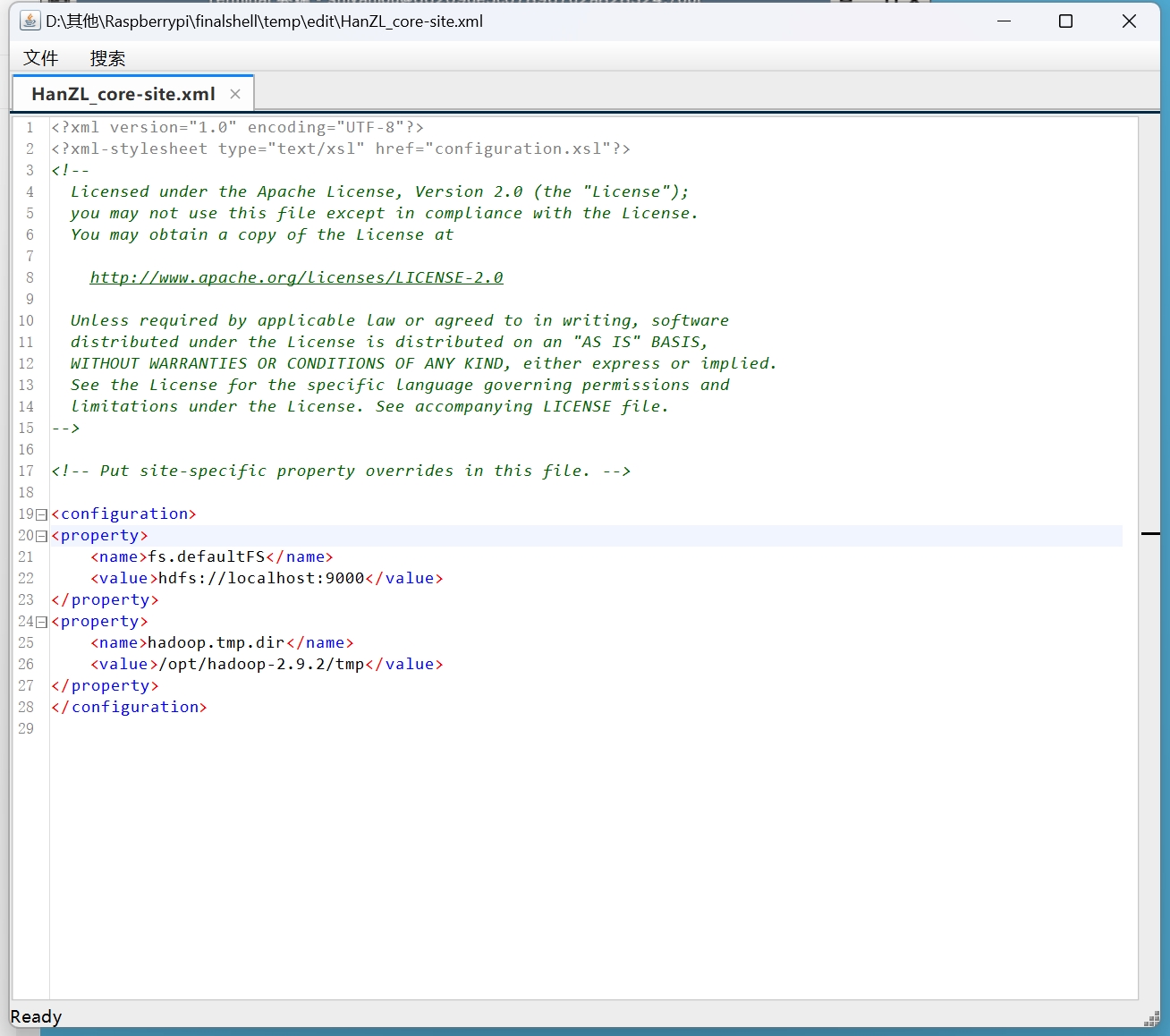
第 3 步:配置 hdfs-site.xml。
1 | <property> |
配置 dfs.replication 指定数据副本的数量,由于是伪分布式形式,只有 1 个节点,所以这里设置为 1 即可。
配置 dfs.secondary.http.address 指定 Secondary Namenode 的地址和端口。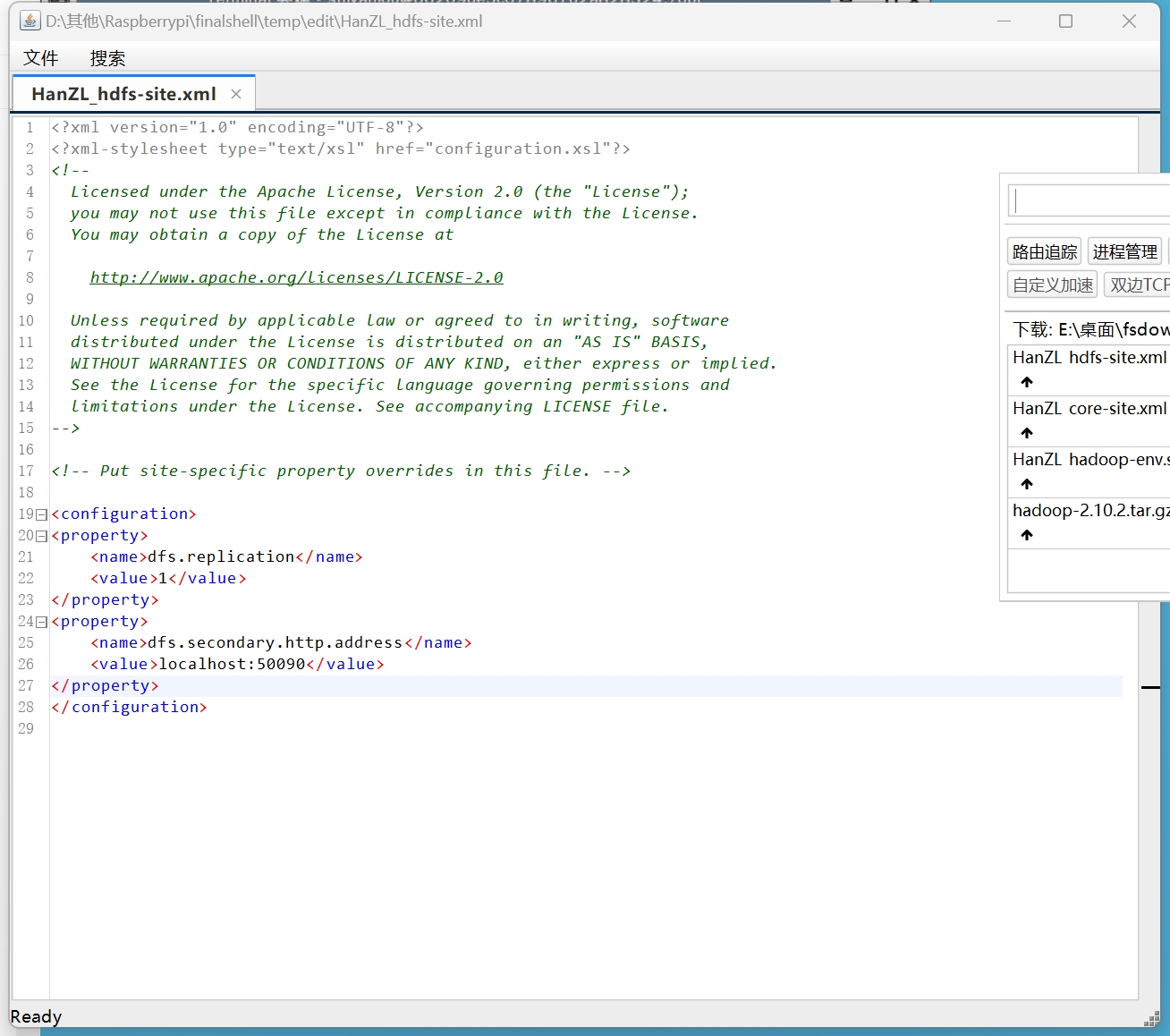
第 4 步:配置 mapred-site.xml。
原文件名为“mapred-site.xml.template”,将其另存为“mapred-site.xml”以使其生效。
确认其内容如下:
1 | <property> |
配置 mapreduce.framework.name 指定 MapReduce 运行在 yarn 上。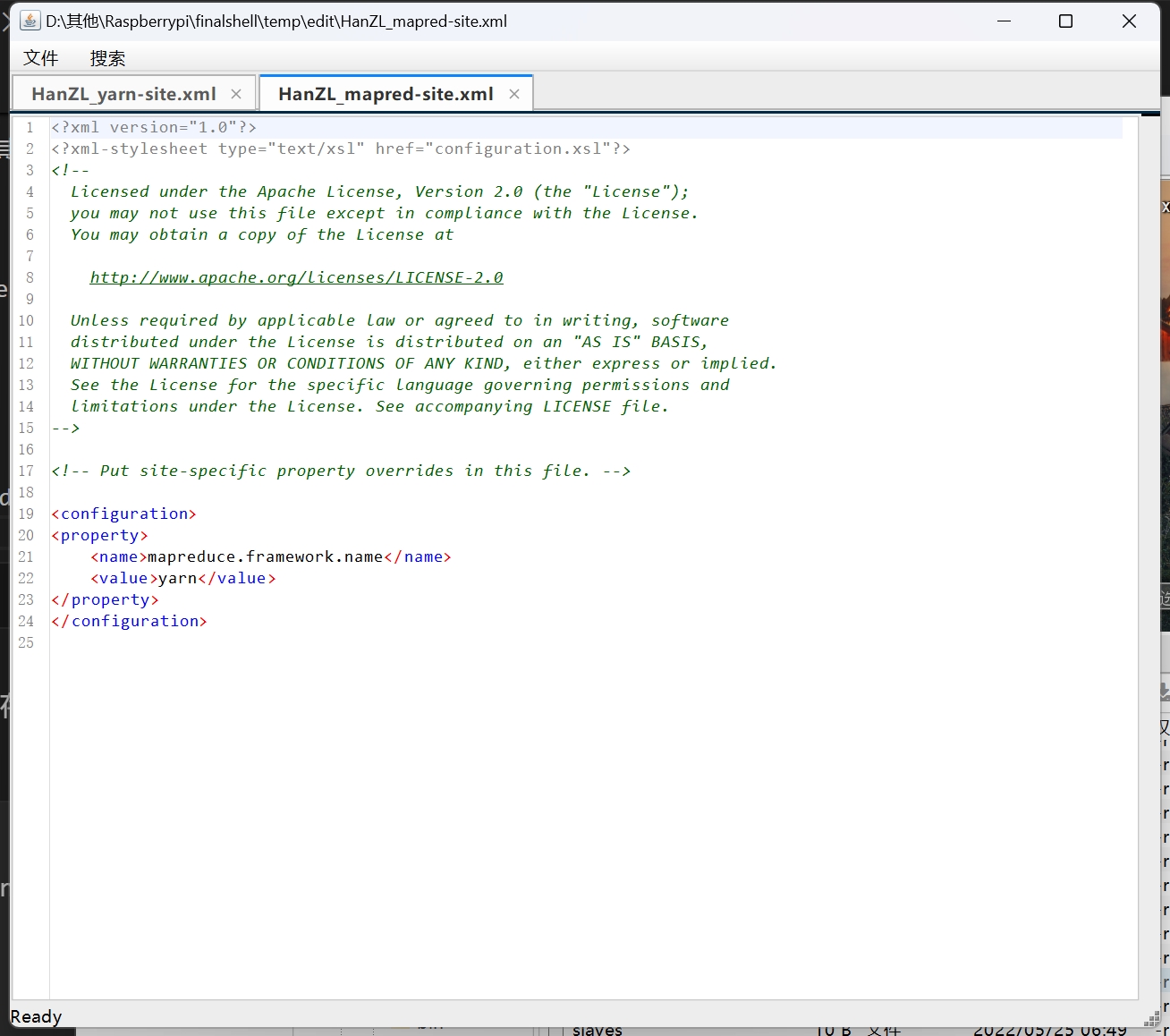
第 5 步:配置 yarn-site.xml。
1 | <property> |
配置 yarn.resourcemanager.hostname 指定 YARN 的 ResourceManager 的地址。 配置 yarn.nodemanager.aux-services 指定 shuffle 机制。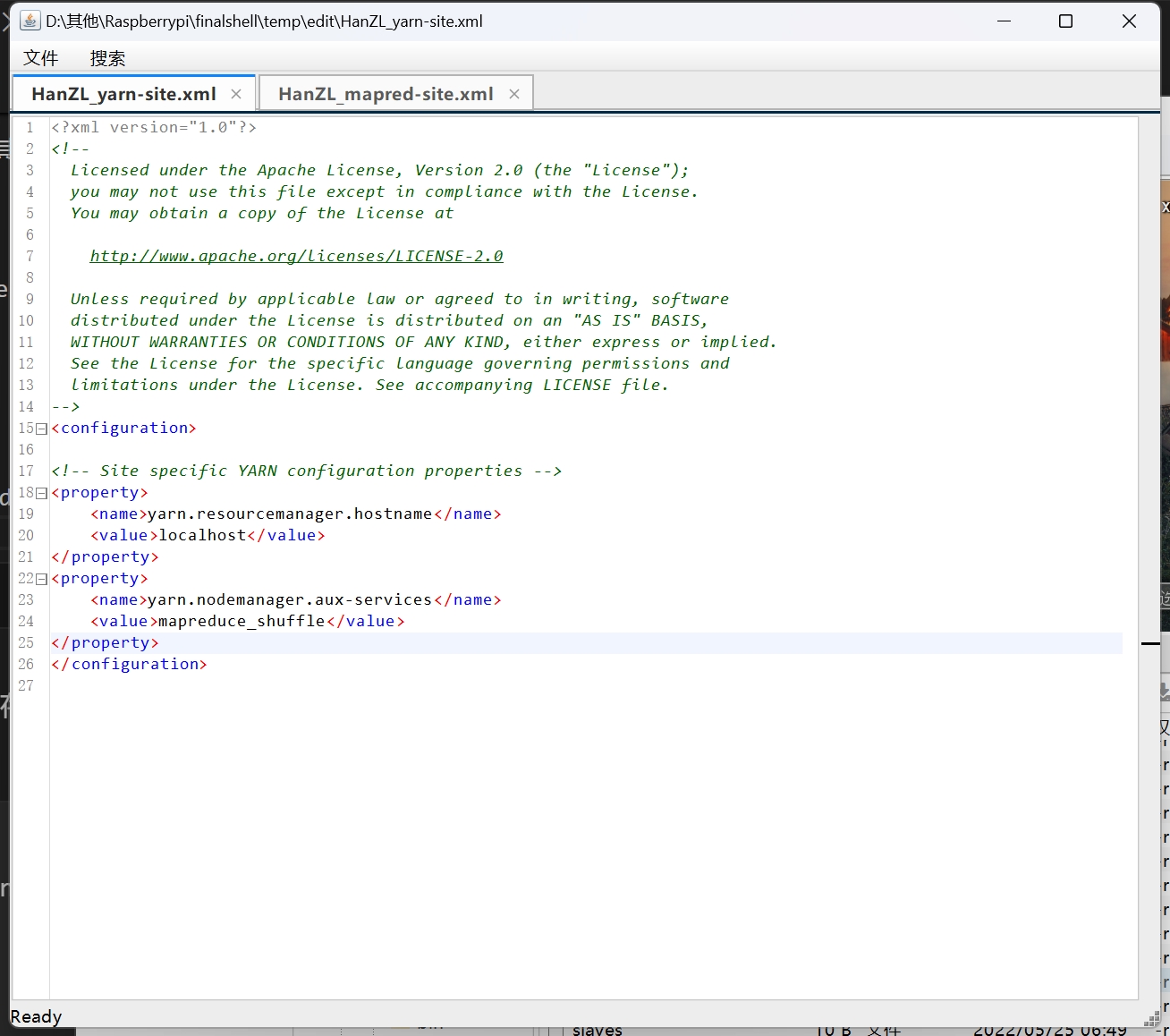
第 6 步:配置 slaves。
1 | localhost |
配置集群中的从节点,一行一个机器名(或 IP 地址)。这里因为是伪分布式模式,所以 localhost 既是主节点,又是从节点。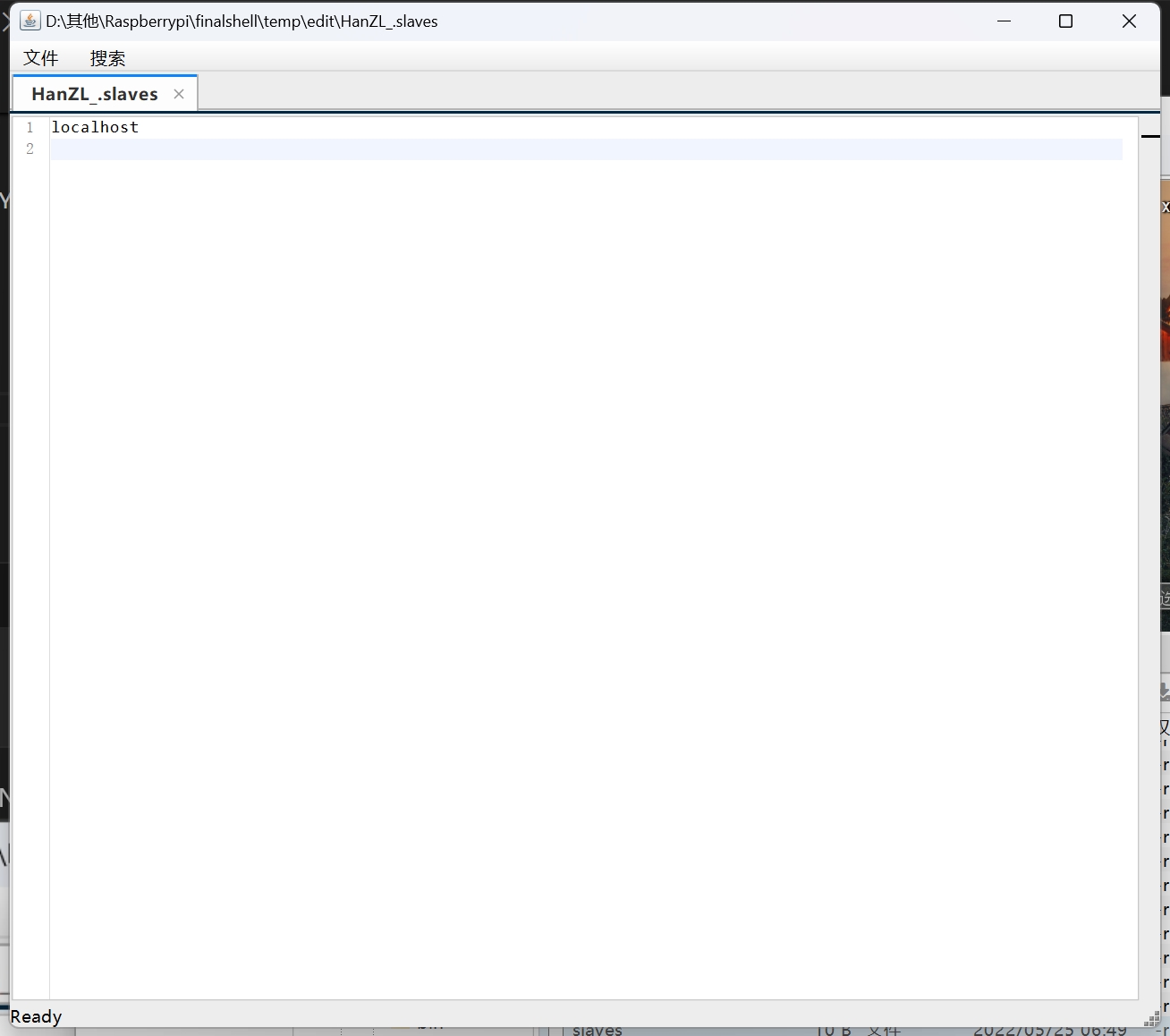
后续操作
格式化文件系统。
在主节点 master 上执行命令“hdfs namenode -format”格式化 HDFS 文件系统。
hdfs namenode -format
执行成功后,会出现 core-site.xml 中 hadoop.tmp.dir 配置项指定的目录。
需要注意的是,格式化只需要一遍即可。如果格式化出错,修改相关配置后,需要先把 hadoop.tmp.dir 配置的目录删除,才能再次格式化。
启动 Hadoop 并验证。
1、首先启动 HDFS:start-dfs.sh
输入root密码
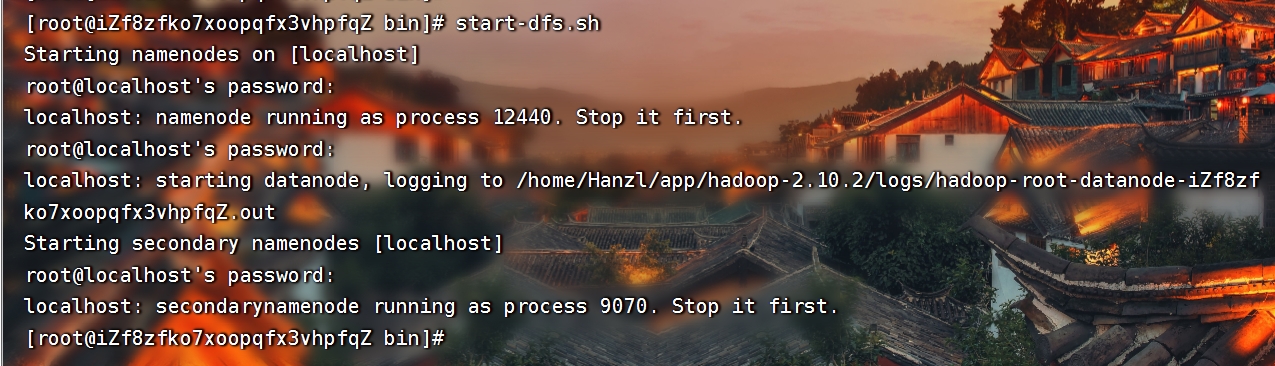
通过输出可以看到 namenode、datanode 和 secondarynamenode 这 3 个进程已经启动了,而且提示了对应的日志文件(*_.out就是日志文件)。如果启动失败,可以去日志文件查看报错信息。
2、启动 YARN:start-yarn.sh
3、验证 Hadoop 是否启动成功:jps
Web 管理工具
HDFS Web UI http://NameNodeIP:50070
YARN Web UI http://ResourceManagerIP:8088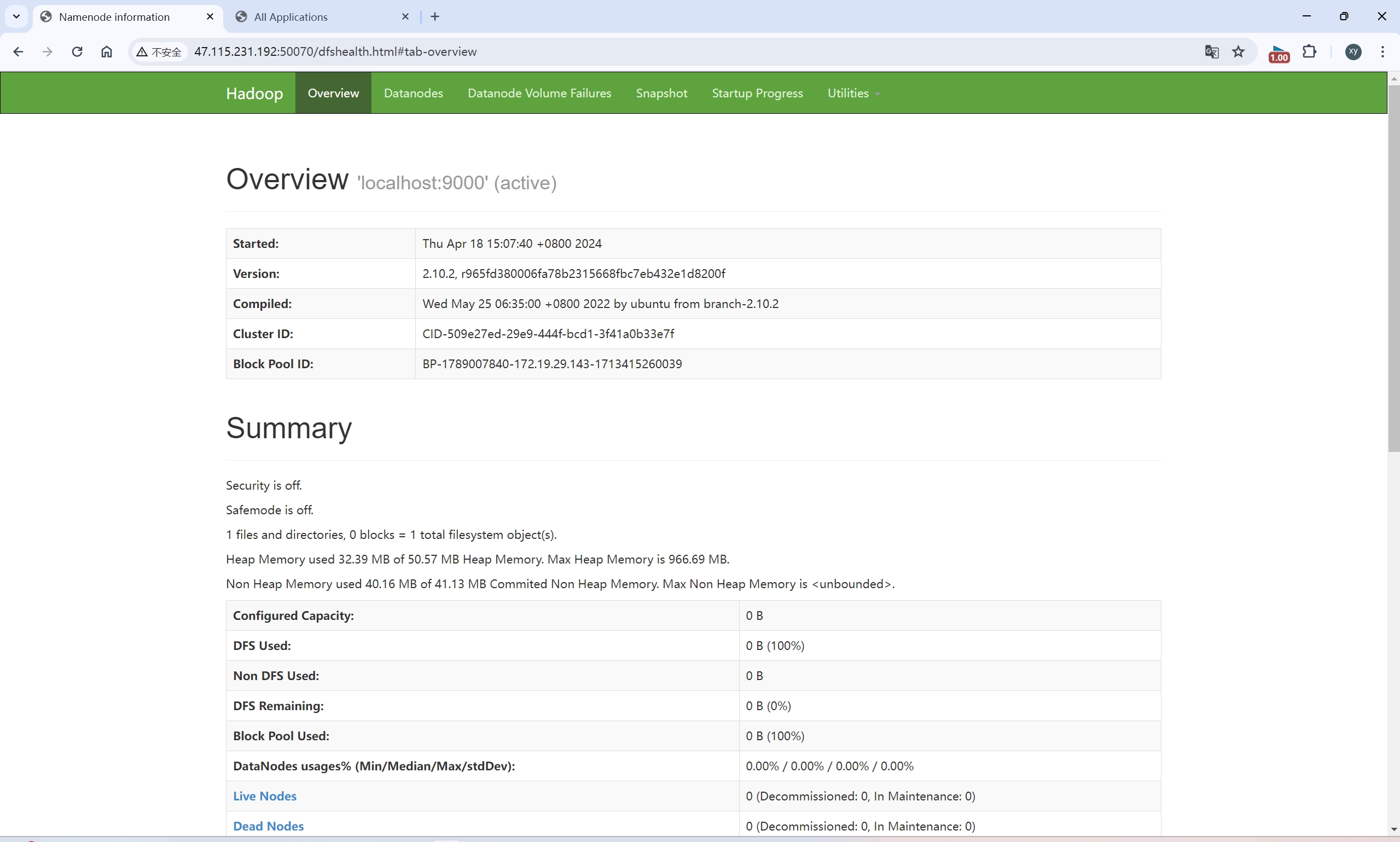
4、关闭stop-yarn.sh
stop-dfs.sh