【Hadoop】全分布式环境搭建
全分布式环境搭建
前言
本案例基于三台阿里云CentOS7,仅作hadoop全分布式搭建的过程命令及技巧总结
这里是 伪分布式集群搭建 没有基础 时间又不着急的小伙伴可以看看
环境
- jdk1.8 (我用的华为镜像 8u202)
- hadoop3.1.3
修改主机名
我们看到网上或者课本上什么slave1 slave2这种是它定义的主机名
我们可以改成自己的
1 | 修改 |
我们可以按照【Hadoop】完全分布式集群搭建 这篇文章里写的 设置hadoop102、hadoop103、hadoop104 三个主机名
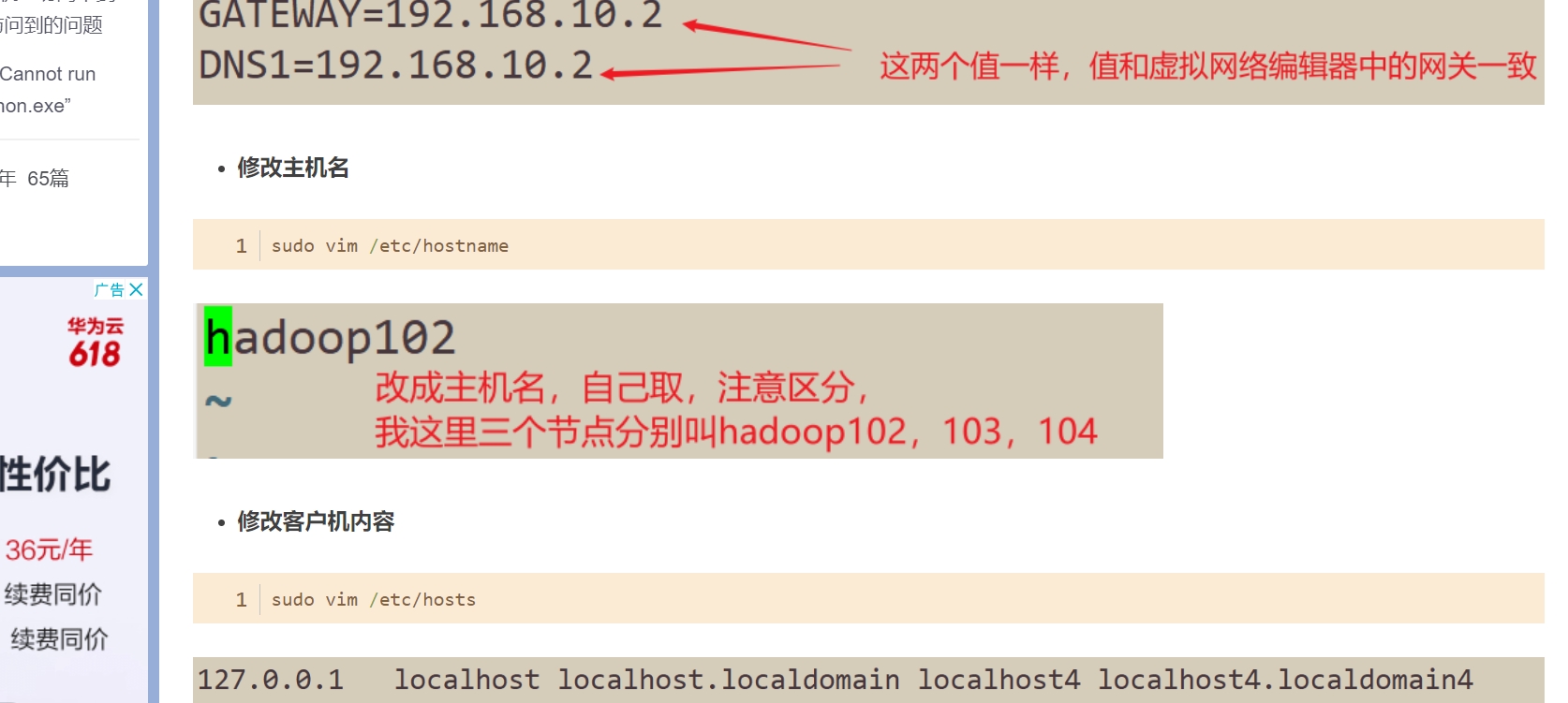
修改hosts文件
这一步是配置主机名对应的ip地址 然后就可以使用主机名来访问IP地址 省去了每次敲IP的繁琐
教程都这么做 你也可以不写 用对应的主机的IP替代
笔者建议 不熟悉的话跟着教程走
1 |
|
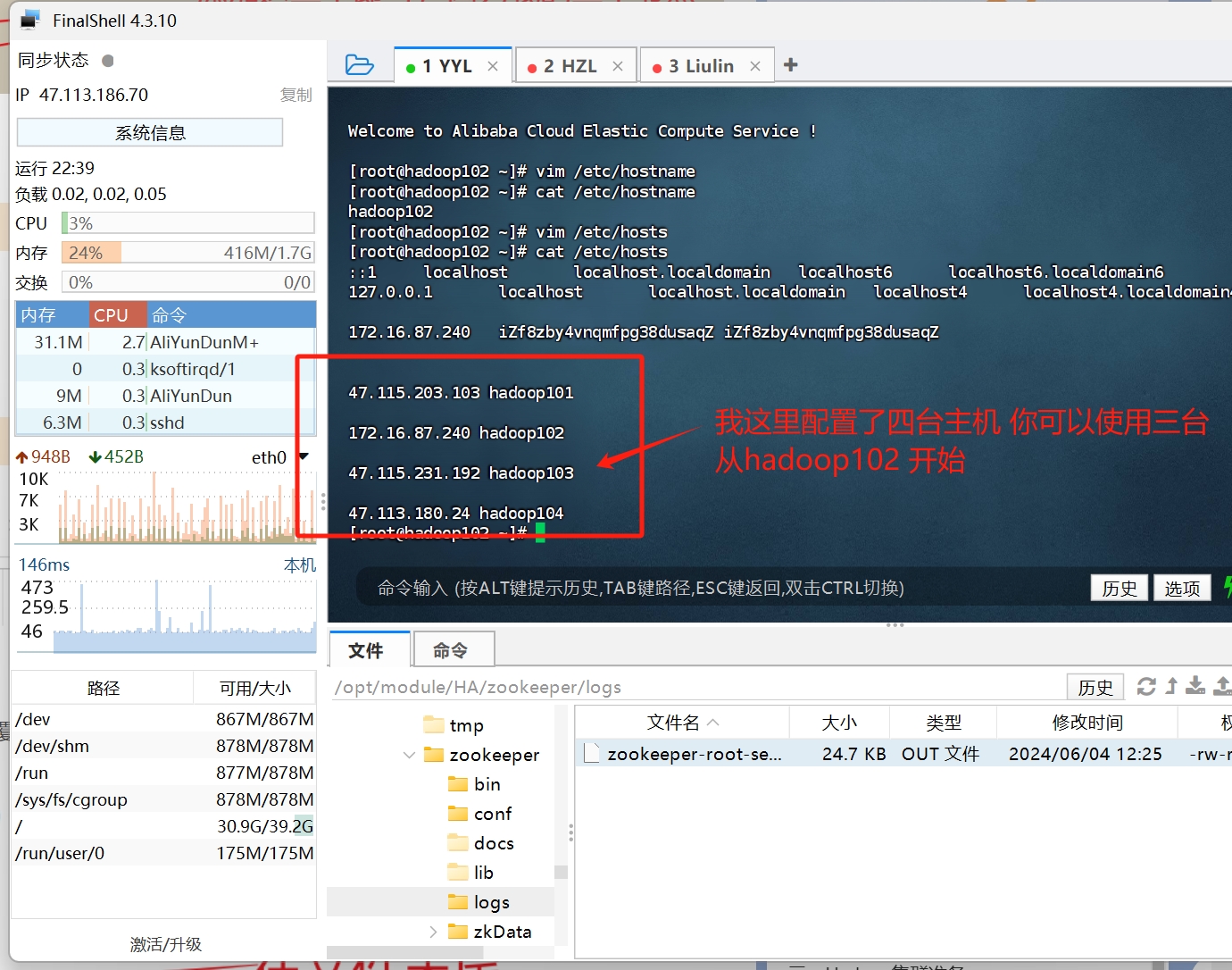
以上两步 需要在每台机器上执行
然后 先进行一个验证 来确保截至目前步骤正确
我们使用ping 命令 来给每台主机 互相ping一下
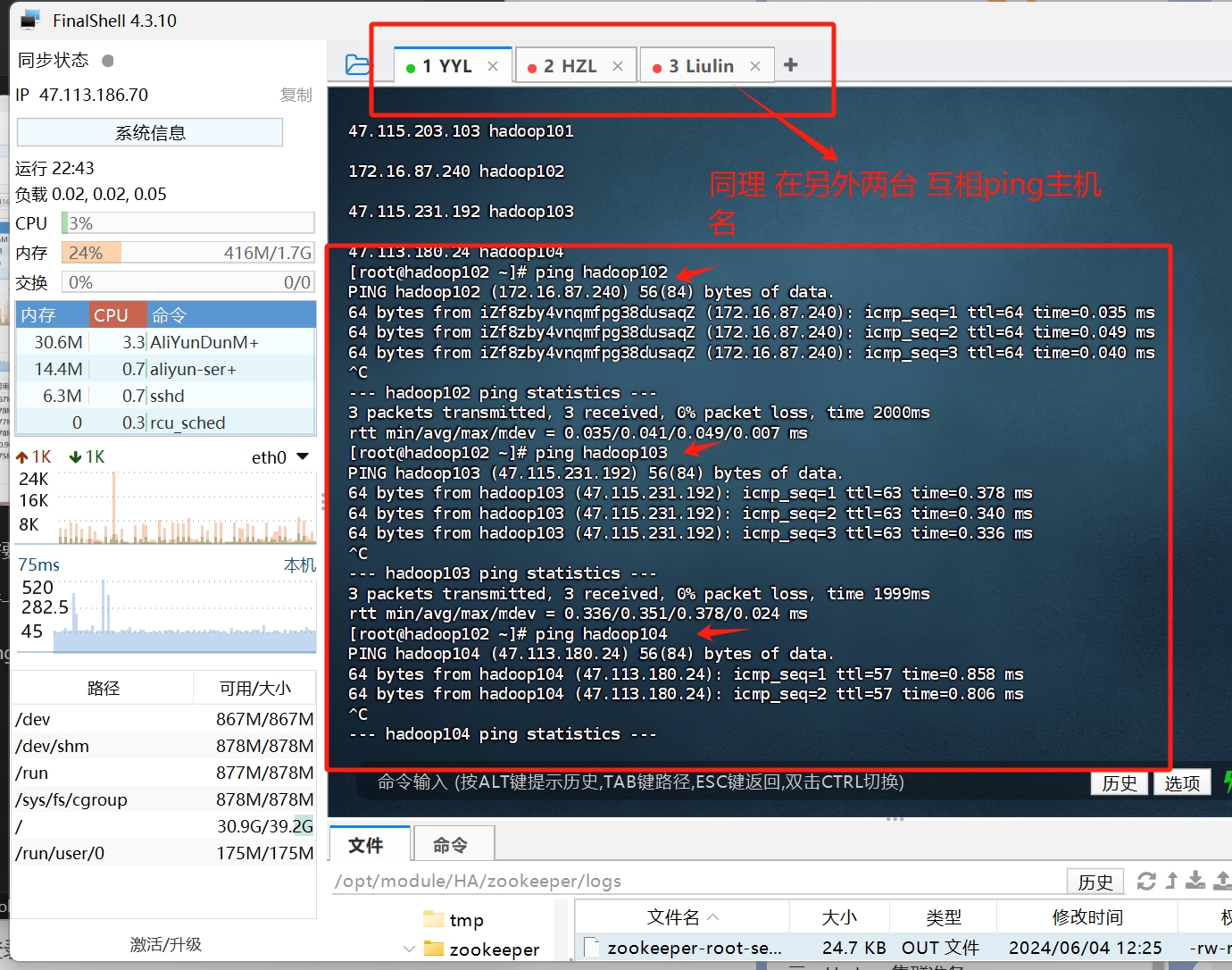
当你看到 每条ping命令都有目标主机IP的响应 那么就证明你前面两个步骤没问题
配置免密登录
这步免密操作 【Hadoop】完全分布式集群搭建 这篇教程写的不详细 我详细演示下
首先我们需要在每台机器上创建一个新的用户: 分别在hadoop101 hadoop102 hadoop103 主机下创建myhadoop01 myhadoop02 myhadoop03 用户
1 | // 创建用户 |
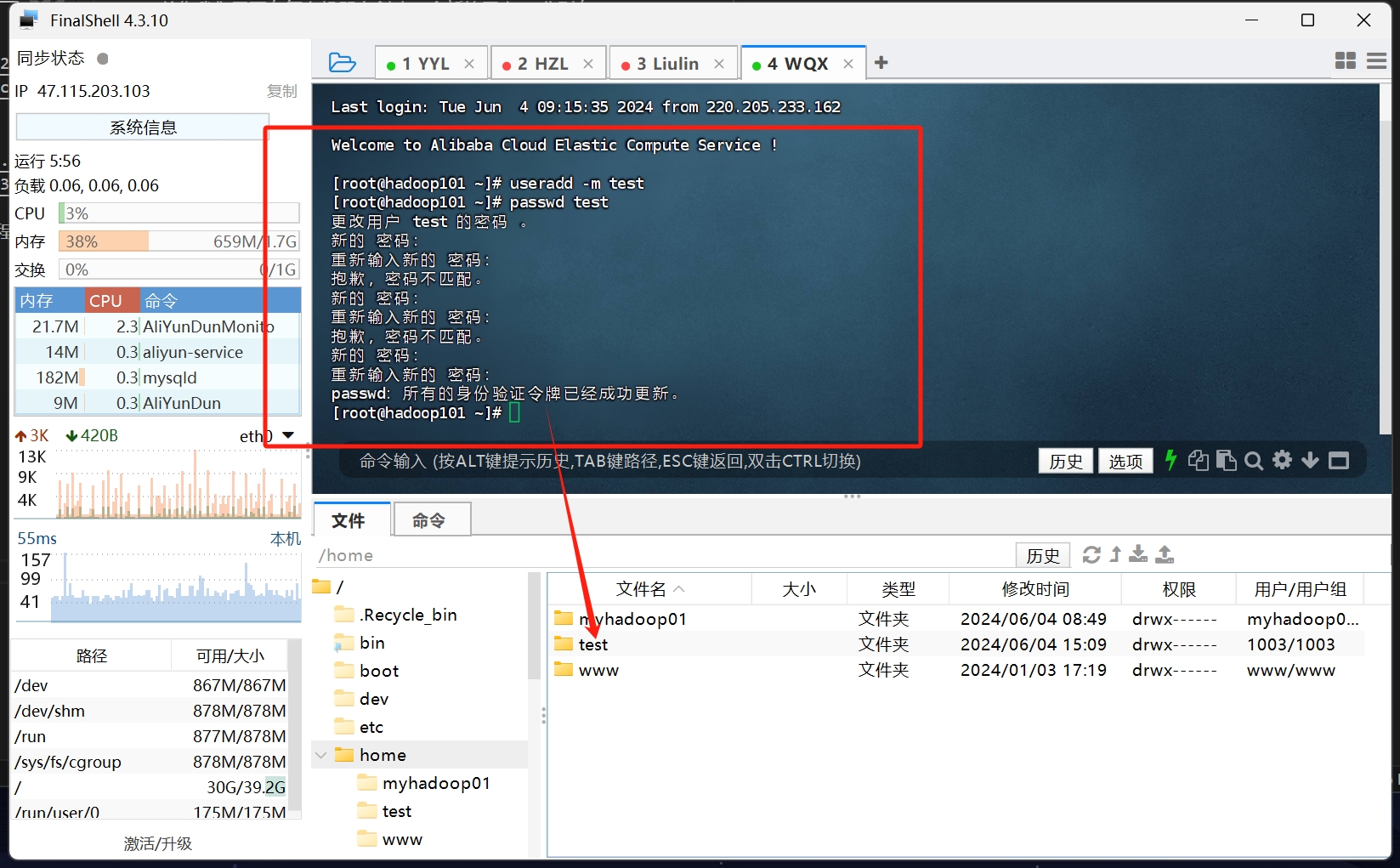
如图所示 在创建用户后 会在/home目录新增出一个以该用户名 的文件夹
就跟你的windows电脑在创建新用户 在C盘的用户里 多出一个那个名字的文件夹 注意 这个叫家目录 在linux里 可以用~表示路径
然后切换到该用户下 su <用户名>
输入ssh-keygen -t rsa 直接三次回车生成ssh密钥
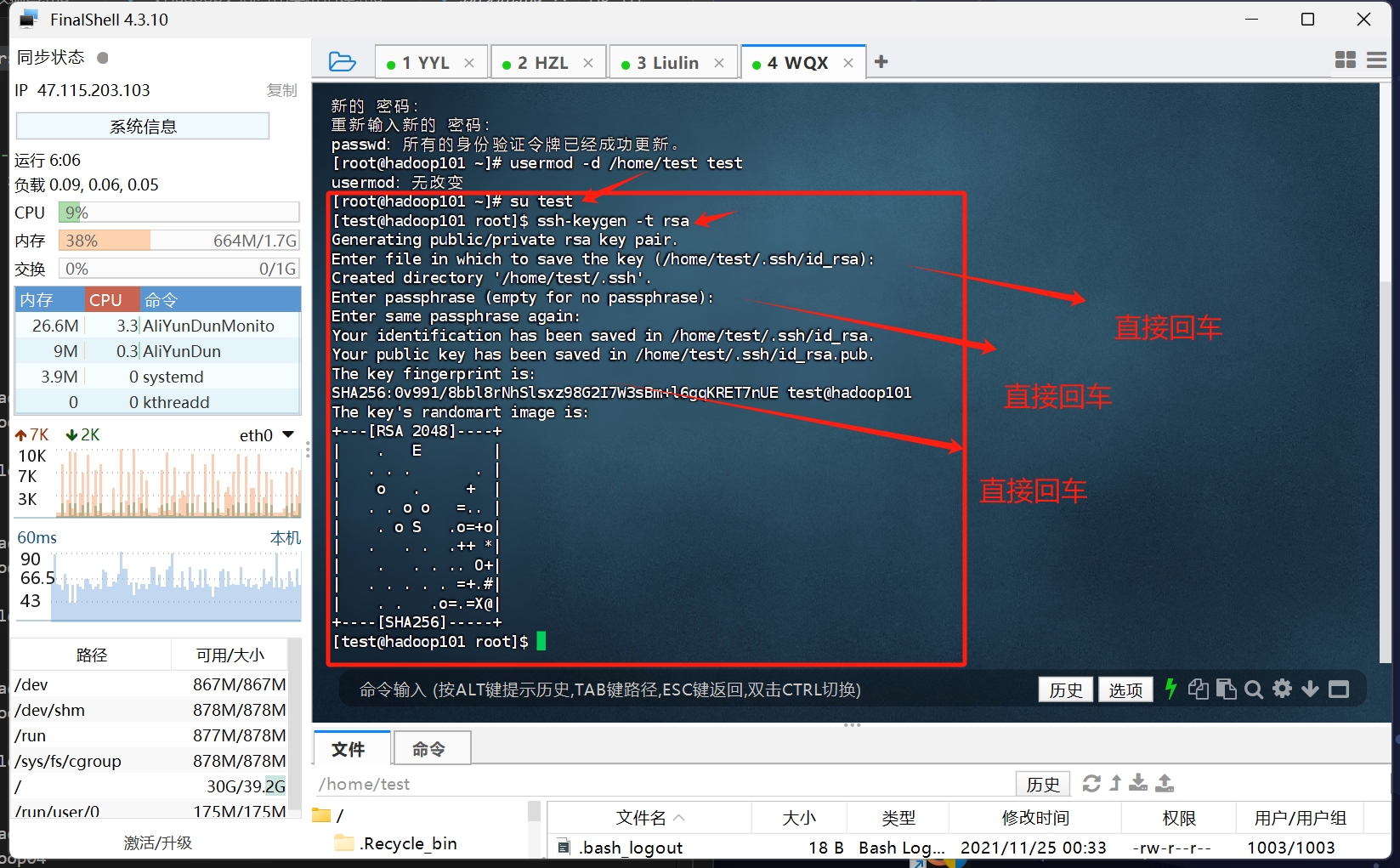
密钥文件 在家目录的.ssh目录下
这里演示的部分 就是我的/home/test/.ssh 目录
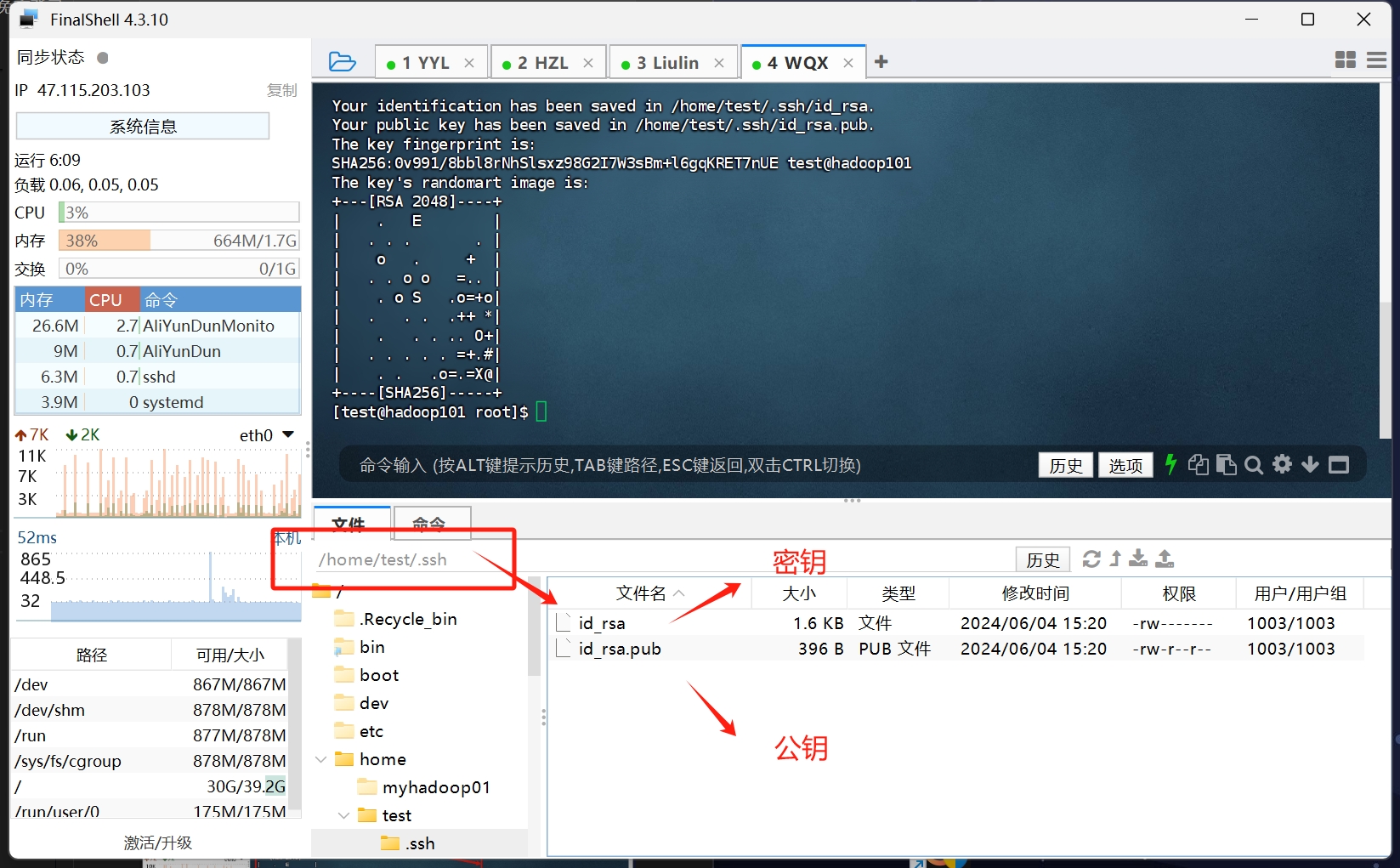
这一步我们需要将每台机器上都如此操作 生成ssh密钥
然后 将myhadoop01的密钥文件id_rsa.pub 分发到每台主机的目标用户的authorized_keys文件里
1 | 进入密钥文件目录 |
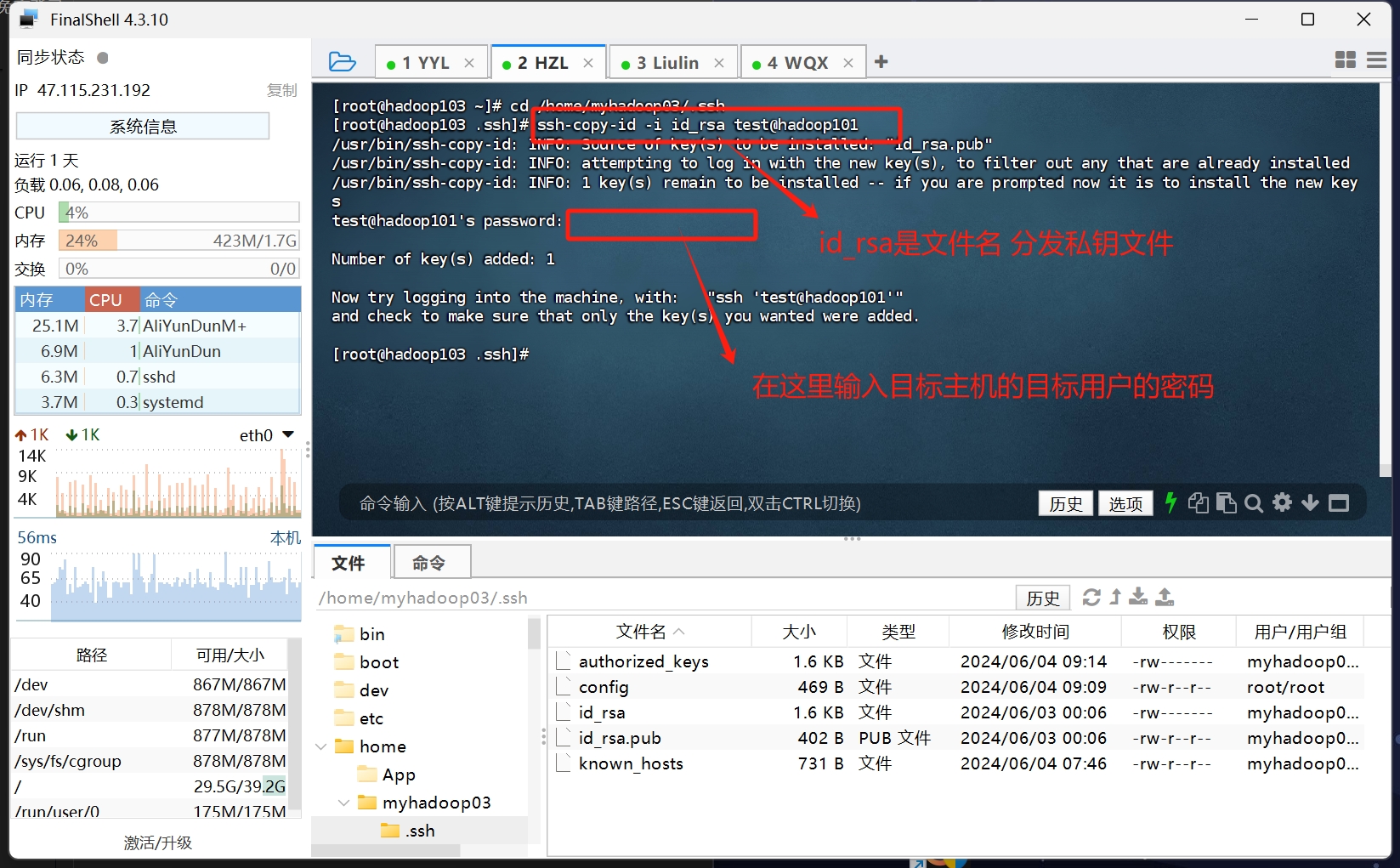
当看到目标主机的那个用户目录出现authorized_keys文件时 就说明分发成功了
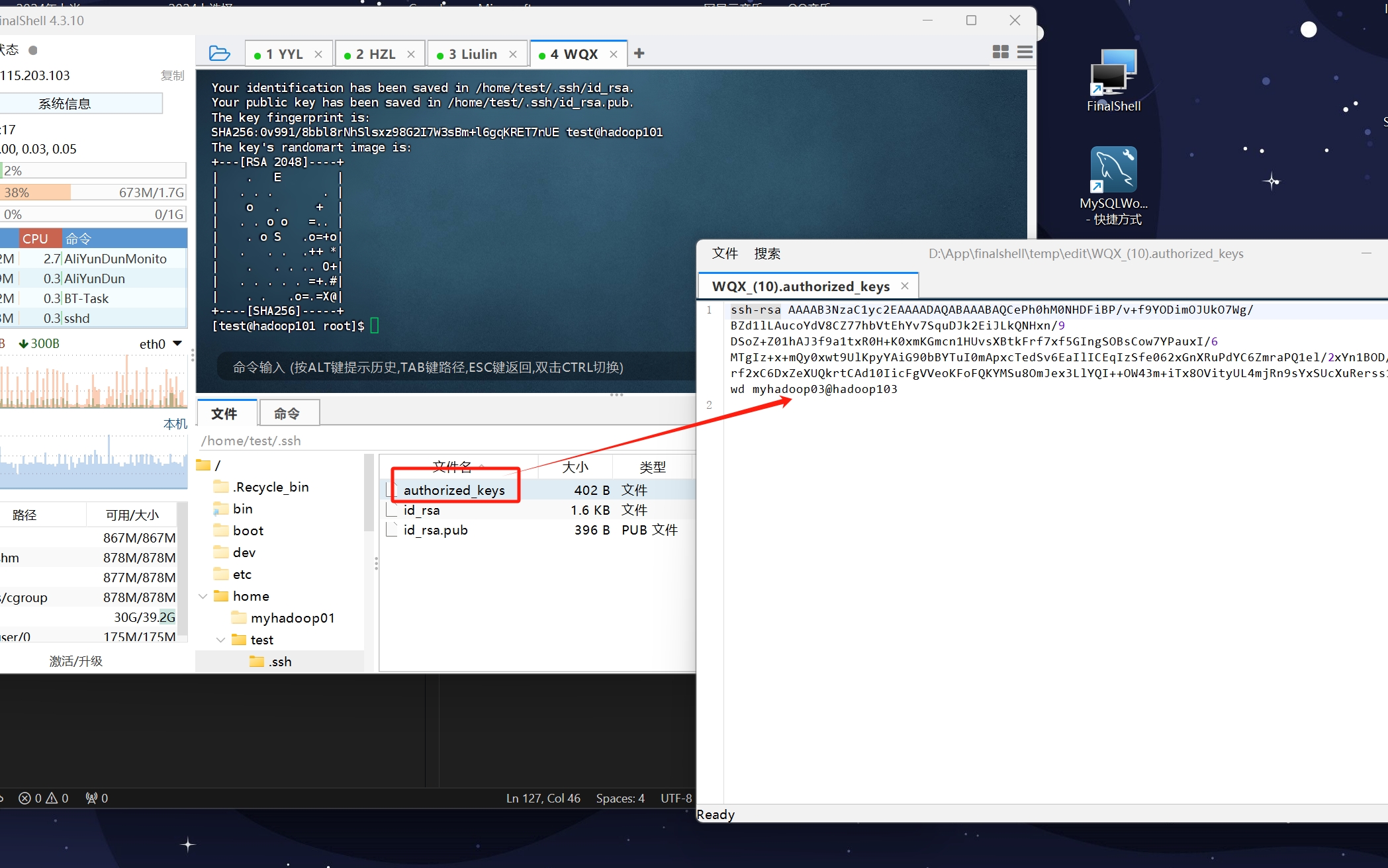
这里演示的是其他主机分发密钥到我现在操作的这台主机的test用户家目录
同样的 这步操作 需要每台主机 互相之间都要分发密钥 这样才能实现每台主机之间免密登录
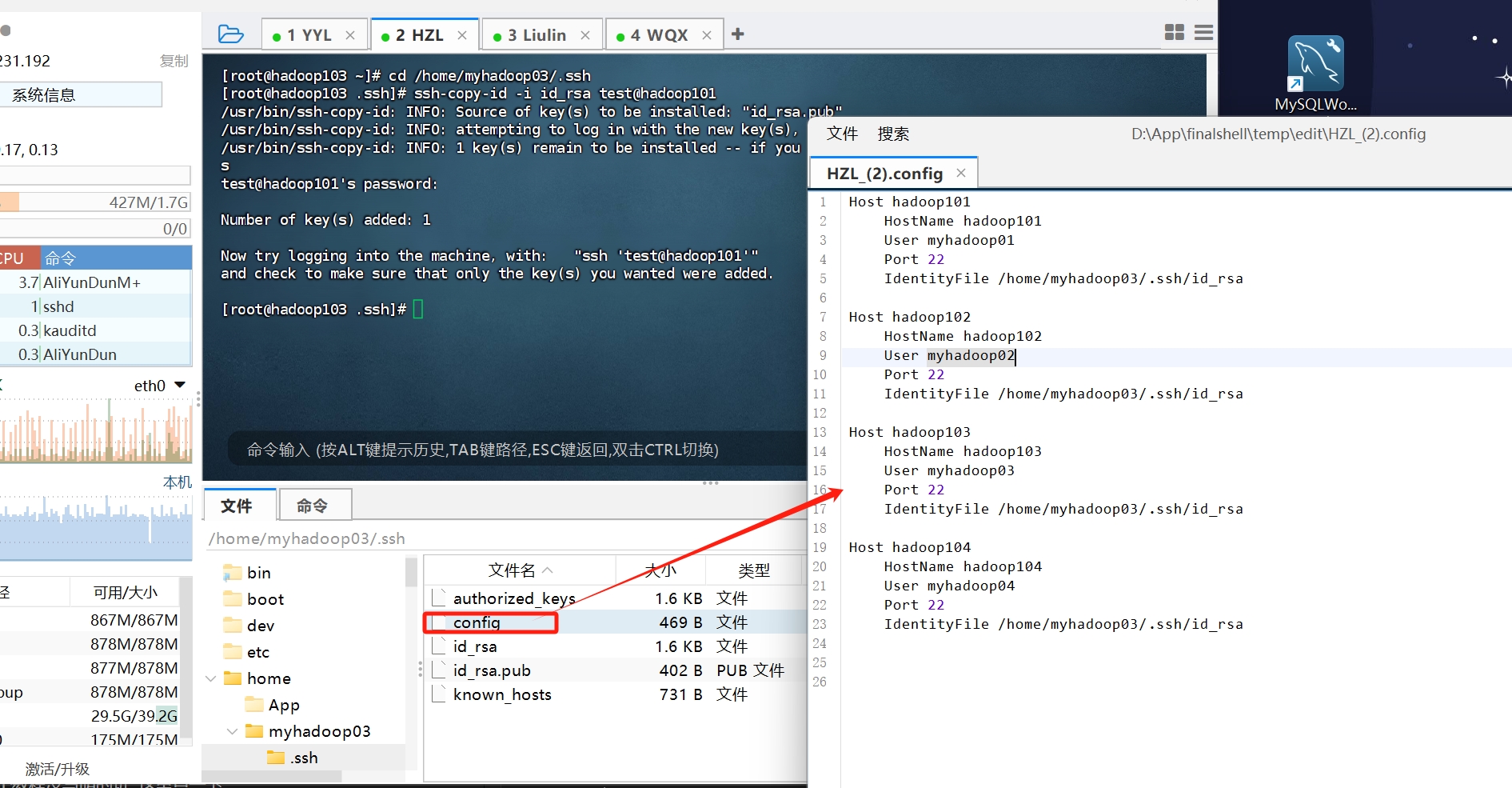
同时 我们还需要在.ssh目录下创建 config文件 配置 免密登录的账户 主机 IP信息
就按照下面的格式 自己写吧 分别是主机名 用户名 还有 目标机器的端口号和密钥文件路径
这一步 一定一定不要照抄的一股脑复制昂 至少 每个机器的ssh密钥目录都是不一样的 所以 理解着来复制
1 | Host hadoop101 |
tips:【Hadoop】完全分布式集群搭建 这篇教程使用了分发的脚本 我菜 所以就手动操作了 有能力的可以去具体看看
最后 我们来验证下这步是否成功
让我们直接在终端里 直接 ssh <主机名>
如果是这样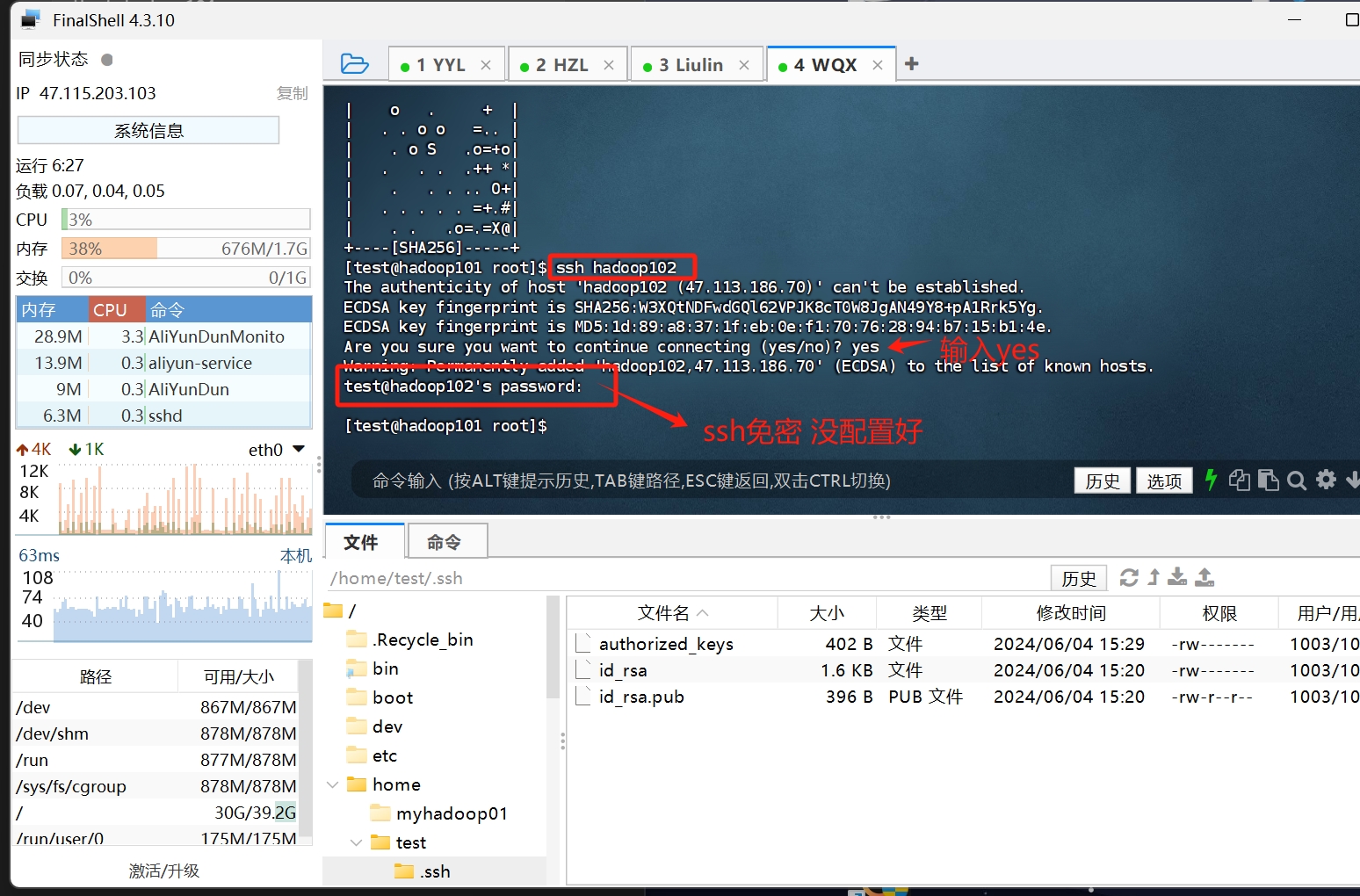
那么 你反复对照这一节的步骤 解决一下问题
如果是直接就登上了 那就恭喜你 免密登录成功了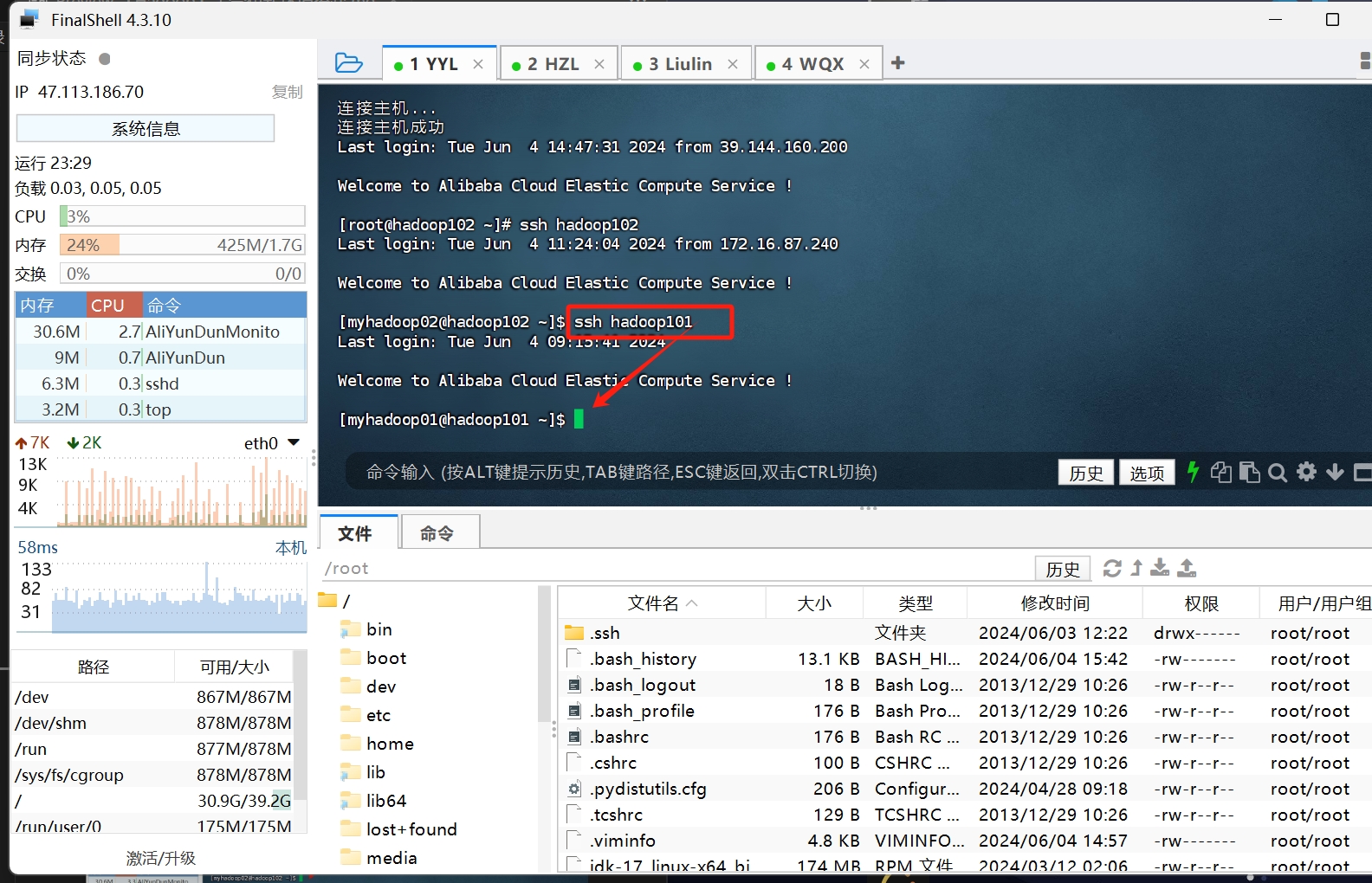
ps: 因为我搭建的环境是服务器 不是虚拟机 所以我遇到了一个教程没写明的坑 这里点一下 在/etc/hosts文件里 本机的地址 需要换成内网IP 不然 在启动namenode进程的时候 会显示端口被占用 我在这里卡了半天..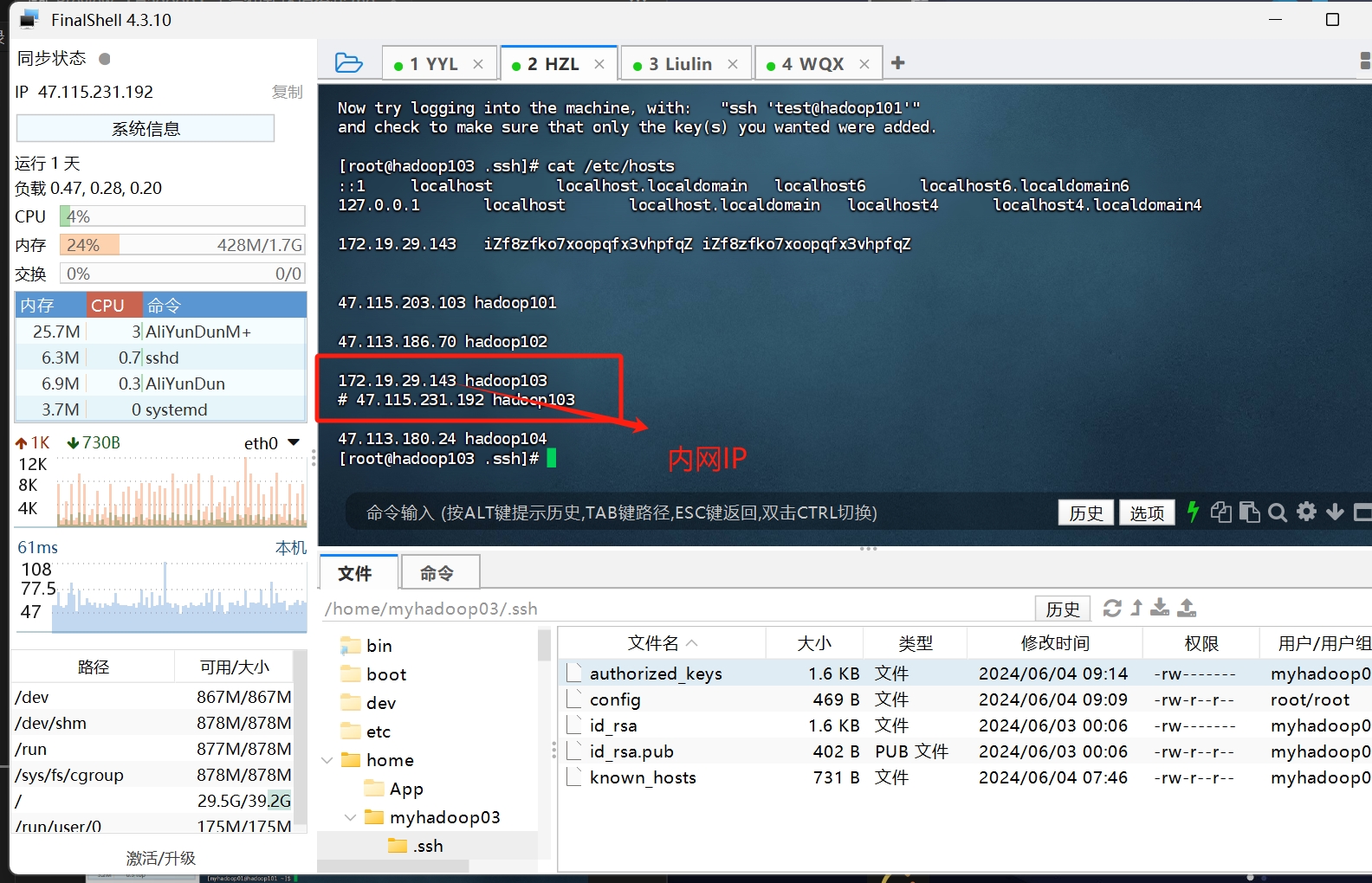
安装jdk1.8和hadoop3.1.3
这里直接使用压缩包 手动配置环境了
资源链接我会一起打包附在底部
按照【Hadoop】完全分布式集群搭建 的步骤 这两个解压出来的文件是放在/opt/module目录下
那么 解压命令是 tar -zxvf <压缩包名> -C /opt/module
如果报什么什么 /opt/module open 什么什么不存在的 那么就在/opt下创建一个module目录就好了
同理 解压jdk和hadoop都解压到/opt/module目录 然后在/etc/profile文件的文件底部添加环境变量
1 | export JAVA_HOME=/opt/jdk1.8.0_202 |
注意 JAVA_HOME和HADOOP_HOME要换成你实际的安装路径
然后 source /etc/profile 更新环境变量
验证一下
1 | [root@hadoop101 opt]# java -version |
能看到对应的java和hadoop的响应版本号 就OK了 如此操作每台机器 (同样的 这步也可以用【Hadoop】完全分布式集群搭建 提到的脚本去一键分发配置文件)
配置全分布式集群
hadoop配置文件在hadoop的安装目录的/etc/hadoop目录下
我们主要需要修改四个文件 core-site.xml 、 mapred-site.xml 、 hdfs-site.xml 、 yarn-site.xml
- core-site.xml
1 | <configuration> |
- mapred-site.xml
1 | <configuration> |
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<configuration>
<!-- nn Web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
</description>
</property>
<!-- 2nn Web端访问地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>yarn-site.xml
1 | <configuration> |
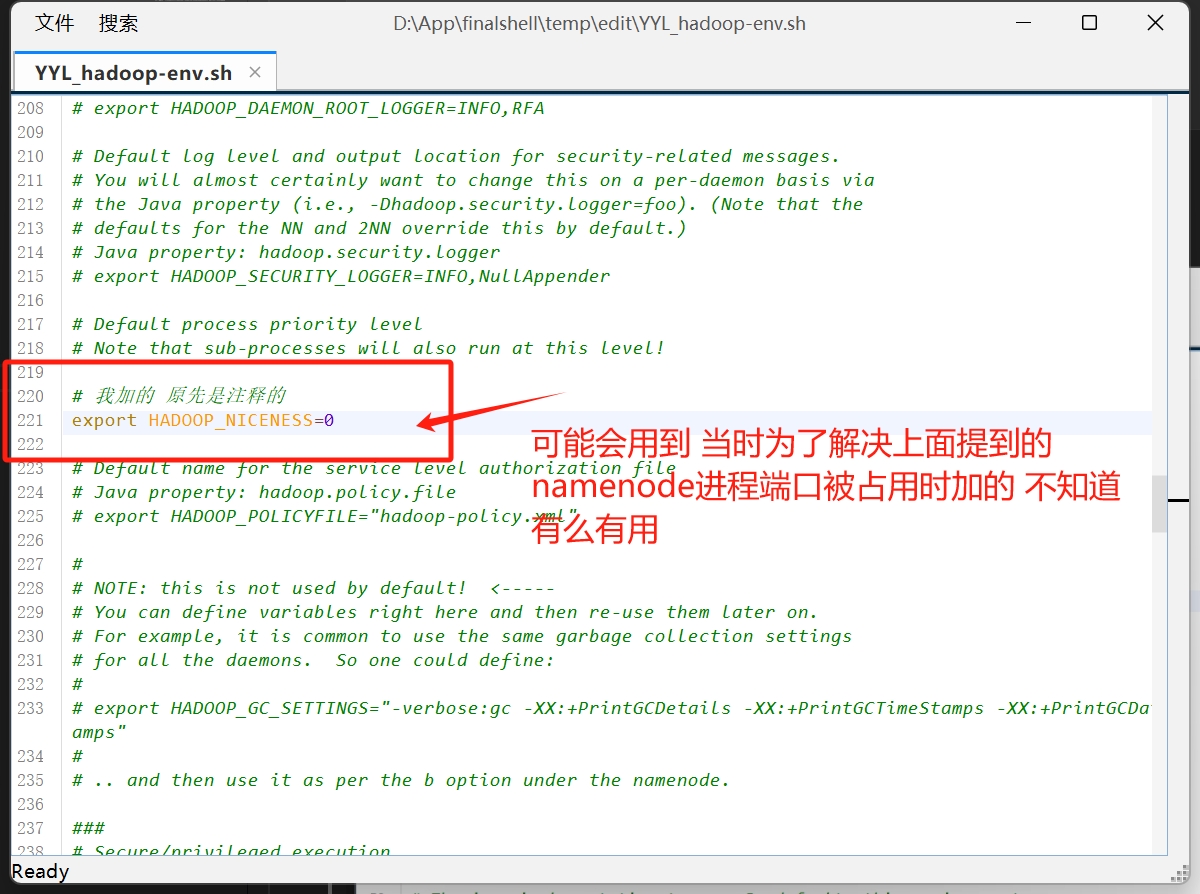
然后 这四个文件配置完后 我们还需要在hadoop-env.sh添加java的安装目录
大概在38行 JAVA_HOME=/usr/lib/jvm/jdk-17-oracle-x64

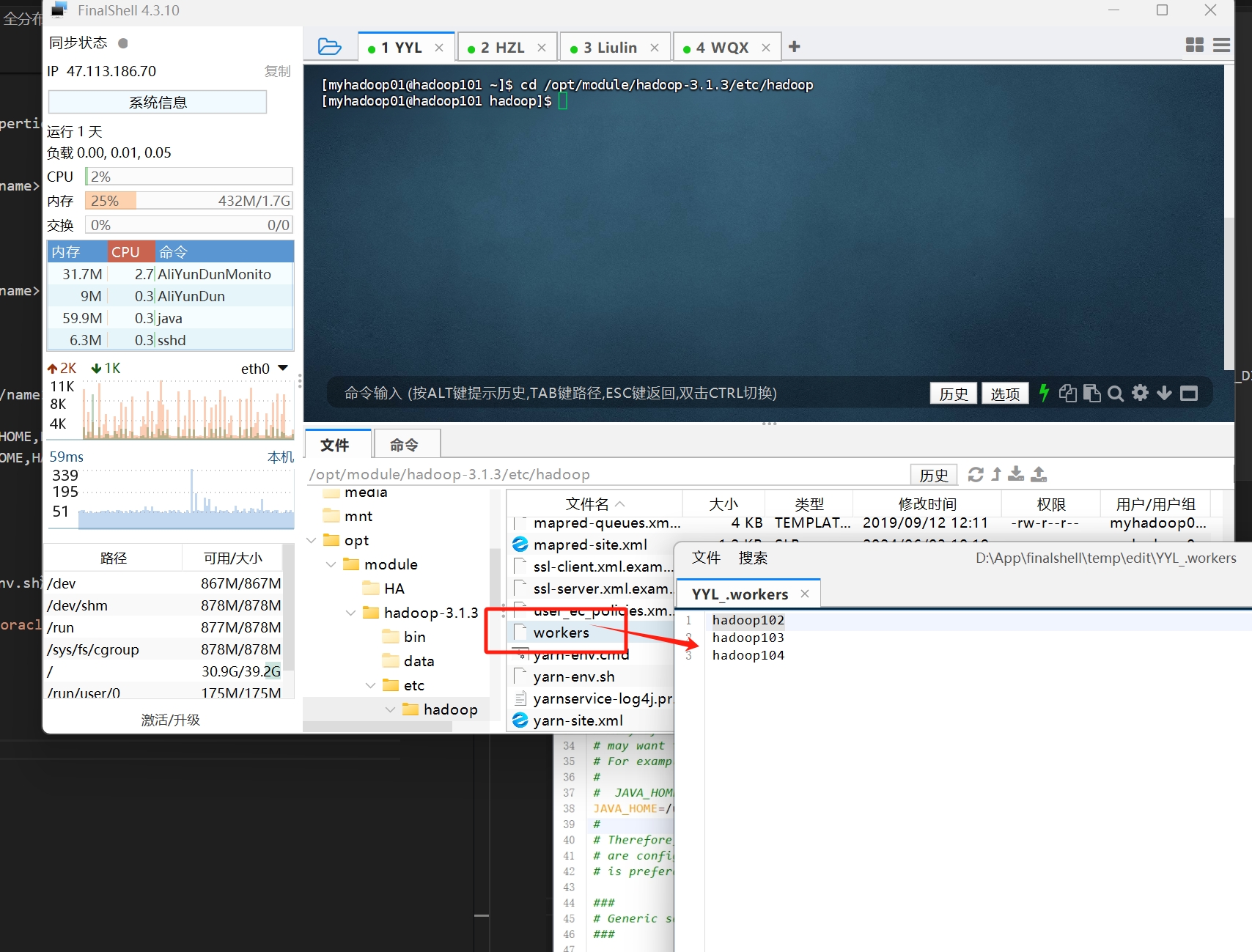
还有workers文件 这里是配置yarn的节点
然后 配置完以上文件后 我们就可以格式化hadoop的文件系统了
格式化 hdfs namenode -format
只需要在一台服务器上格式化就行了

这个是集群的各个进程服务的规划
文件格式化之后 可能需要手动创建下/opt/module/hadoop-3.1.3/data目录 这个目录用来存储hadoop的数据 同时 我们需要给它分配对应的权限 方便起见 直接将这个文件的所有权分配给我们最开始创建的hadoop用户
1 | chown -R myhadoop02:myhadoop02 /opt/module/HA/zookeeper/zkData |
以上文件的配置在另外两台机器上配置过后
按下面这张教程的截图的命令 进行启动
注意 只需要在第一台服务器启动hdfs服务 第二台启动yarn服务
cd /opt/module/hadoop-3.1.3/
sbin/start-dfs.sh
sbin/start-yarn.sh

当按这个步骤启动后 使用jps命令能查到以下进程 那么恭喜你 已经搭建好了hadoop全分布式集群
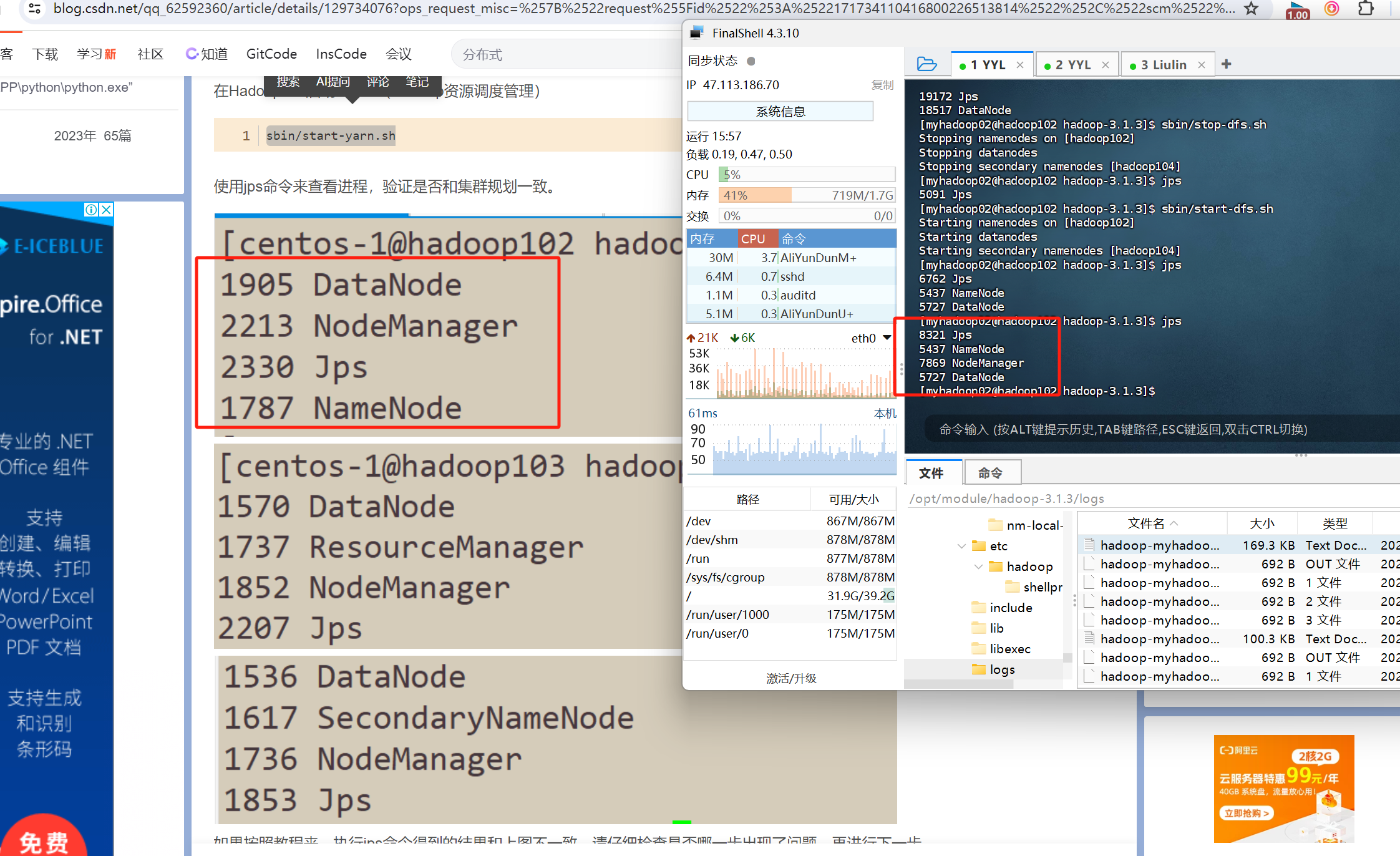
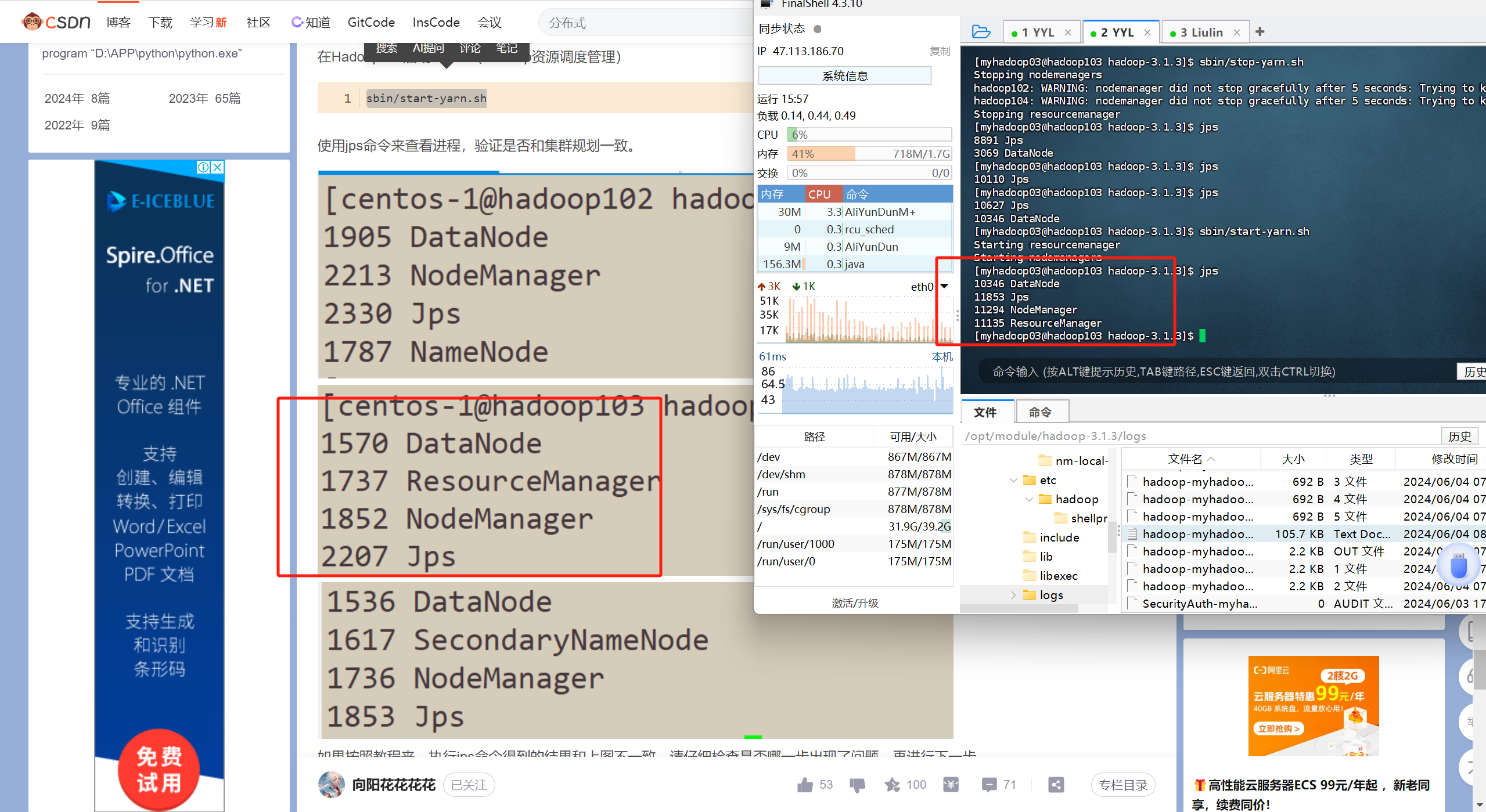
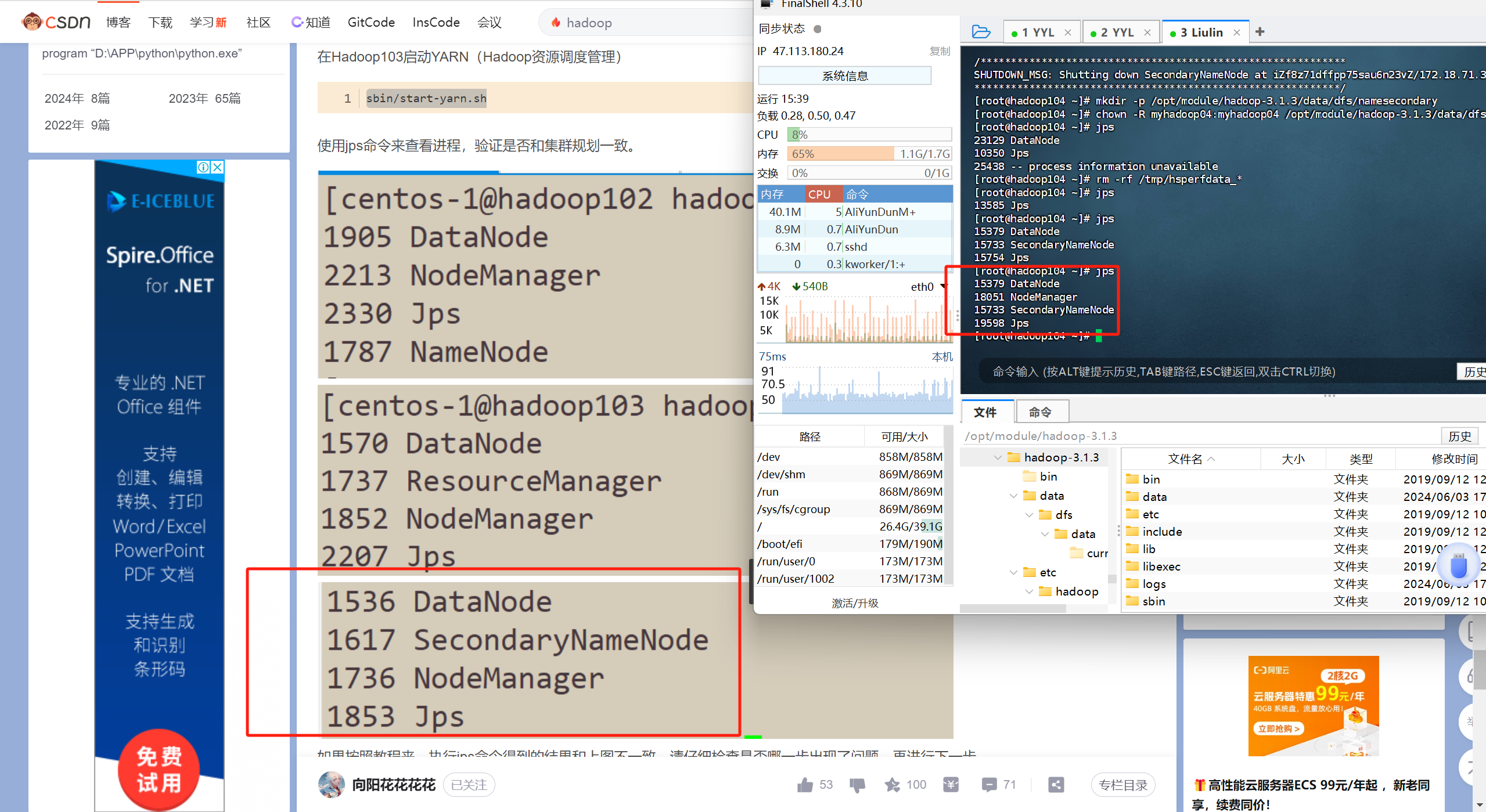
问题排错
我这个教程呢 也不是包对的 遇到问题还得自己解决 总之呢 教程里写的配置文件的内容呢是包没问题的 但是犯各种小细节的错误 所以 如果你遇到问题 不知道怎么解决 那么 去查看日志 根据日志的内容信息 去网上搜 都有前人踩过的坑 贴出来的
日志在 hadoop安装目录的logs下 即/opt/module/hadoop-3.1.3/logs/目录下 去查看你对应的进程的日志就好了
tips:日志太长看不懂?现在不是有AI么 把最新的一次启动的日志 复制出来 贴给AI问它怎么回事 我们只需要知道是什么问题 对应的去解决就好了