【Hadoop】高可用集群搭建
前言
本案例基于三台阿里云CentOS7,仅作hadoop高可用集群的搭建过程命令及技巧总结
本篇以全分布式集群为基础 这里是我写的 全分布式集群搭建笔记
参考了CSDN上的一些帖子 以及多篇博客 根据自己的实际搭建过程总结的 有需要的小伙伴可以看看 希望能帮到你
环境
jdk1.8
hadoop3.1.3
zookeeper3.5.7
搭建全分布式
这个我已经搭建好了 如果你没有准备好 先去完成这一步 可以参考我的 笔记
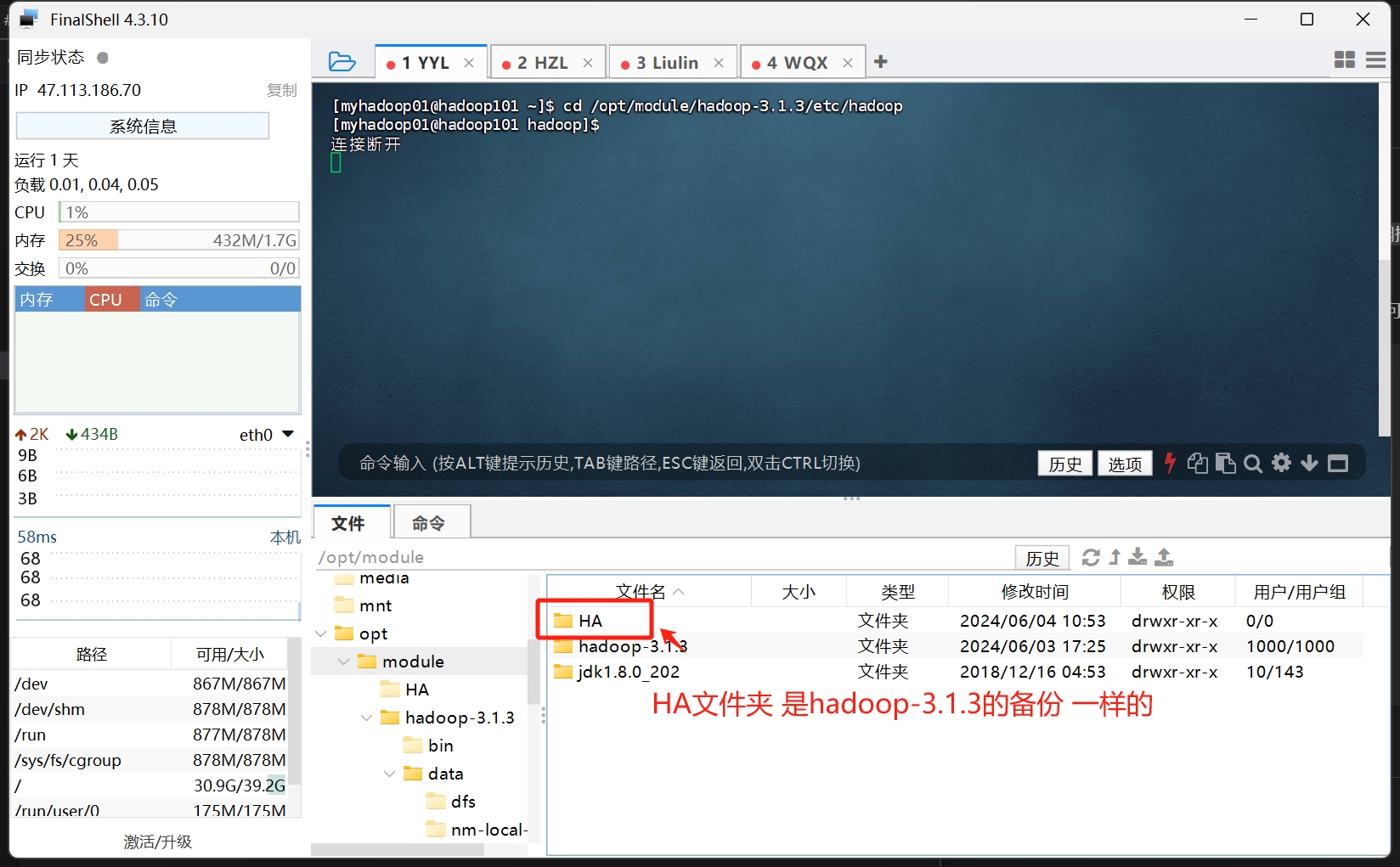
在完成全分布式搭建后 我们先复制一份这个服务的安装文件 按网上的教程说就是 哪怕高可用搭建不出来 至少还能还原分布式可用
所以 我们用cp命令将每个机器上的hadoop安装文件都复制一份 在复制出来的文件里进行高可用集群搭建
1 | 复制原文件为HA目录 |
安装zookeeper
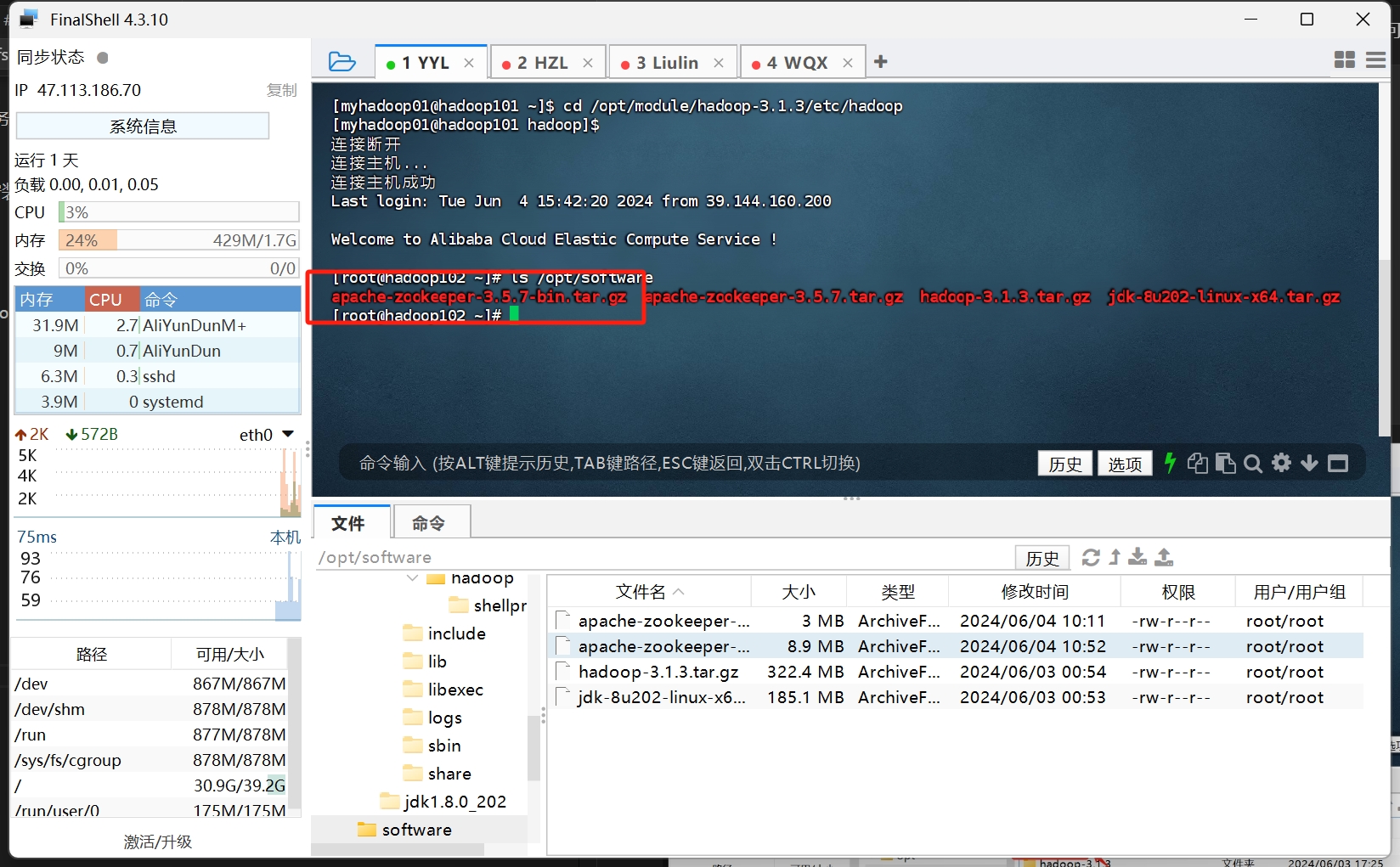
解压zookeeper至/opt/module/HA/目录
tar -zxvf <文件名> -C <解压目录>
注意使用带bin的压缩包 另个用不了 说是类似源码 找不到jar包 什么class对象 避坑
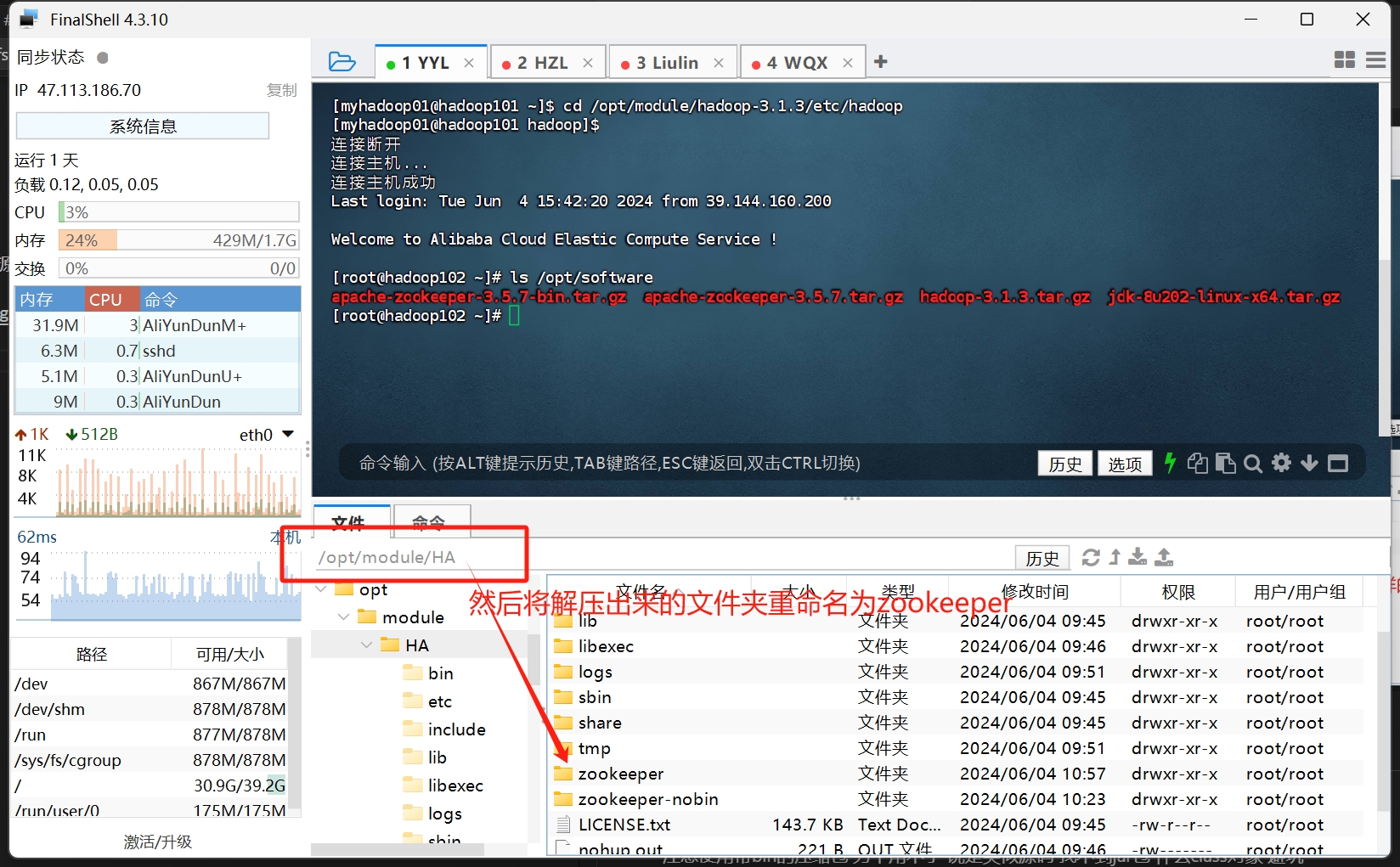
然后 重新配置hadoop在系统环境的安装地址 vim /etc/profile
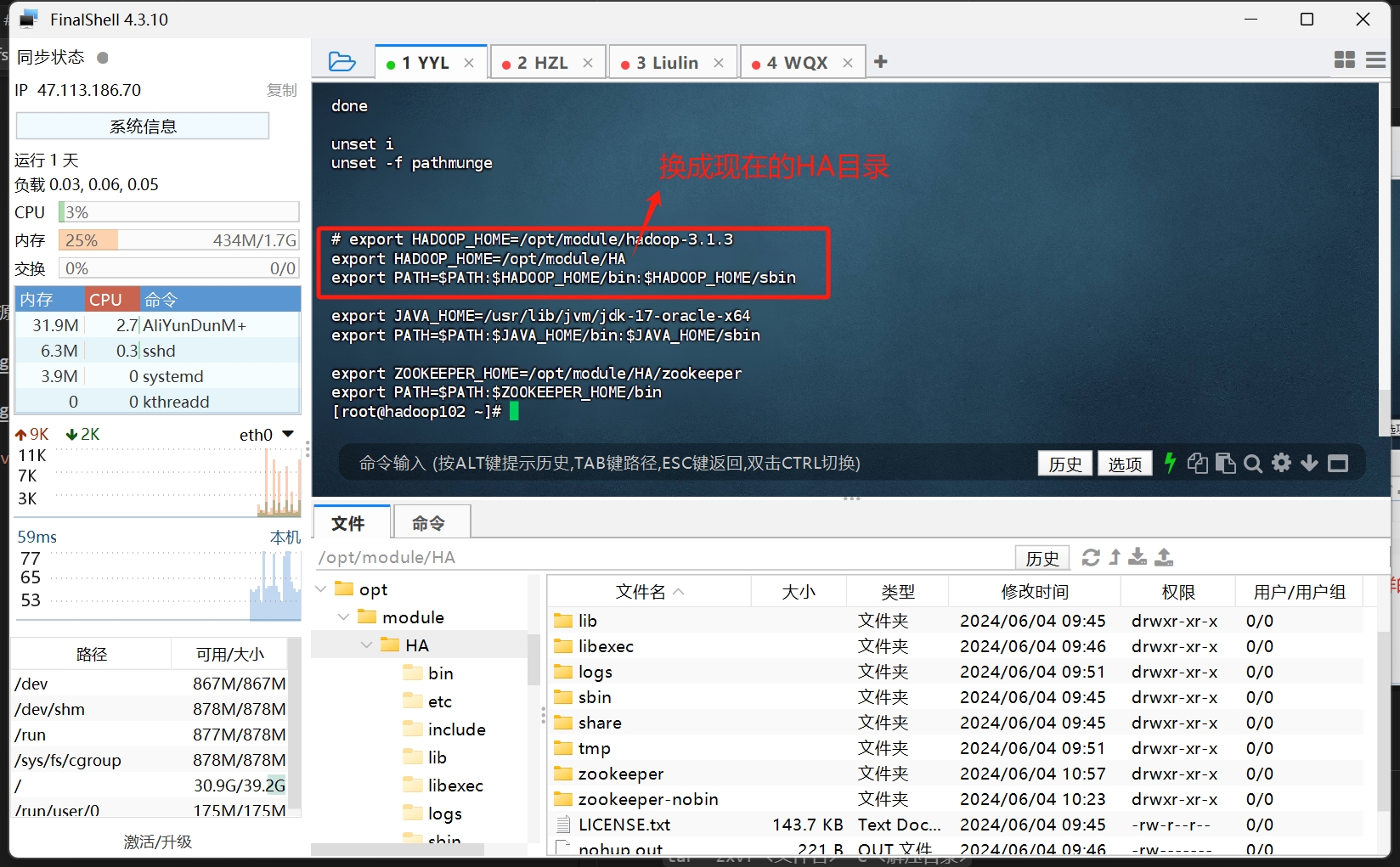
同样的 输入hadoop version能打印出对应的环境地址 即可
1 | [root@hadoop102 ~]# hadoop version |
配置zookeeper
我们需要修改原hadoop的hdfs-site.xml 和 core-site.xml文件
同样的 现在目录就变成了 /opt/module/HA/etc/hadoop 这个目录下
hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87<configuration>
<!-- 集群名称,此值在接下来的配置中将多次出现务必注意同步修改 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 所有的namenode列表,此处也只是逻辑名称,非namenode所在的主机名称 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- namenode之间用于RPC通信的地址,value填写namenode所在的主机地址 -->
<!-- 默认端口8020,注意mycluster1与nn1要和上文的配置一致 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop102:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop103:8020</value>
</property>
<!-- namenode的web访问地址,默认端口9870 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop102:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop103:9870</value>
</property>
<!-- journalnode主机地址,最少三台,默认端口8485 -->
<!-- 格式为 qjournal://jn1:port;jn2:port;jn3:port/${nameservices} -->
<!-- a shared edits dir must not be specified if HA is not enabled -->
<!-- 伪分布式时,取消该配置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop102:8485;hadoop103:8485;hadoop104:8485/mycluster</value>
</property>
<!-- 故障时自动切换的实现类,照抄即可 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 故障时相互操作方式(namenode要切换active和standby),这里我们选ssh方式 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 修改为自己用户的ssh key存放地址 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/myhadoop02/.ssh/id_rsa</value>
</property>
<!-- namenode日志文件输出路径,即journalnode读取变更的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/module/HA/logs/</value>
</property>
<!-- 启用自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- 解决 DataXceiver error processing WRITE_BLOCK operation src -->
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>8192</value>
<description>
Specifies the maximum number of threads to use for transferring data
in and out of the DN.
</description>
</property>
</configuration>core-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52<configuration>
<!-- HDFS主入口,mycluster仅是作为集群的逻辑名称,可随意更改但务必与hdfs-site.xml中dfs.nameservices值保持一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 默认的hadoop.tmp.dir指向的是/tmp目录,将导致namenode与datanode数据全都保存在易失目录中,此处进行修改 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/HA/tmp/</value>
<!-- <value>/opt/bigdata/hadoopha</value> -->
</property>
<!-- 用户角色配置,不配置此项会导致web页面报错(不能操作数据) sky-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>myhadoop02</value>
</property>
<!-- zookeeper集群地址,这里只配置了单台,如是集群以逗号进行分隔 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop102:2181,hadoop103:2181,hadoop104:2181</value>
</property>
<!-- 权限配置 hadoop.proxyuser.{填写自己的用户名}.hosts hadoop.proxyuser.sky.hosts-->
<property>
<name>hadoop.proxyuser.myhadoop02.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.myhadoop02.groups</name>
<value>*</value>
</property>
<!-- 解决journalnode连接不上,导致namenode启动问题 -->
<!-- 也有可能是网络的问题,参考该文章:https://blog.csdn.net/tototuzuoquan/article/details/89644127 -->
<!-- 在dev环境中出现连不上journalnode问题,添加该配置,以增加重试次数和间隔 -->
<property>
<name>ipc.client.connect.max.retries</name>
<value>100</value>
<description>Indicates the number of retries a client will make to establish a server connection.</description>
</property>
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
<description>Indicates the number of milliseconds a client will wait for before retrying to establish a server connection.</description>
</property>
</configuration>
注意 这两个的配置文件 有需要修改的地方 对着注释 修改自己的情况
配置文件的内容是照着 CSDN上这篇帖子 粘贴的
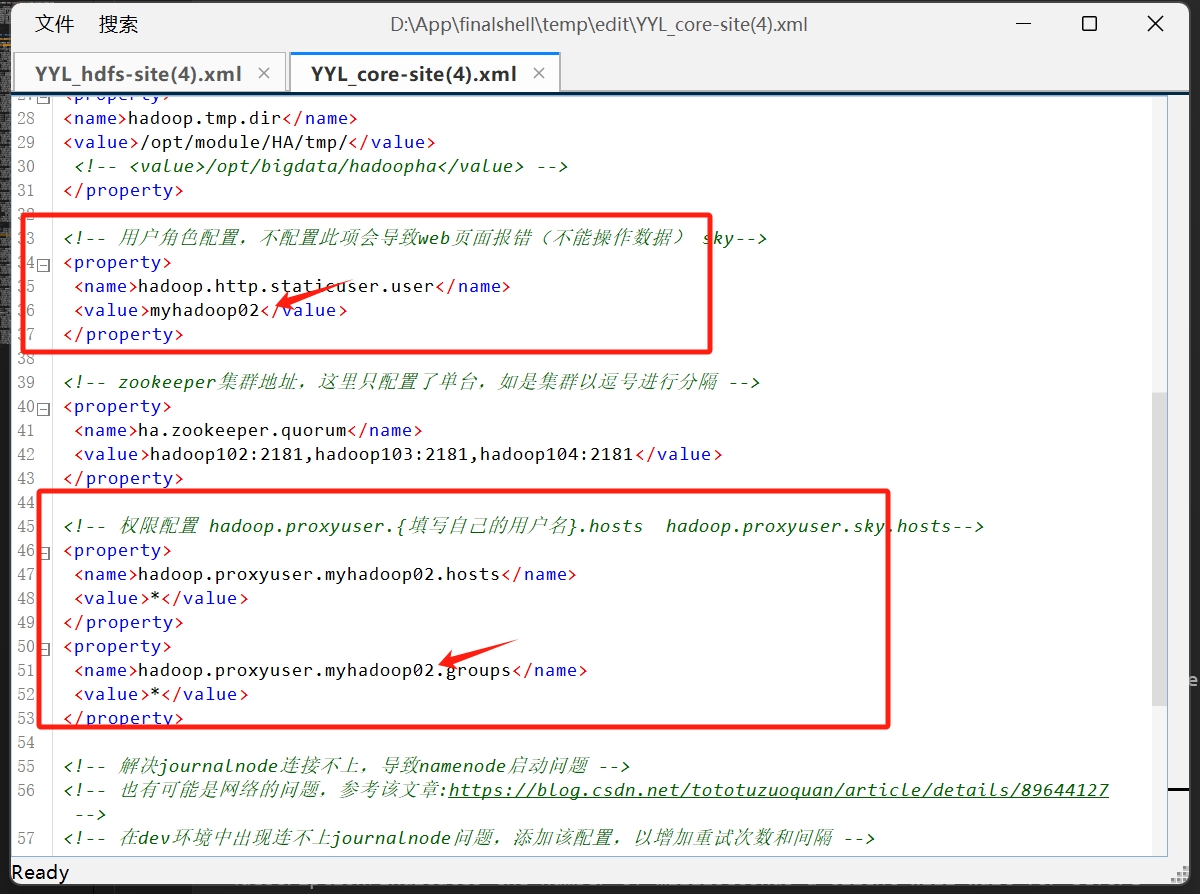
接下来修改hadoop-env.sh文件
在末尾插入以下内容
1 | export HDFS_ZKFC_USER=myhadoop02 |
然后 在
好 至此 以上的所有操作 都需要 分发到所有的机器上
在三台机器都配置完成后 打开2181、2888、3888 端口 或者 直接关闭你的防火墙
复制配置文件 cp zoo_sample.cfg zoo.cfg
修改dataDir的值 dataDir=/opt/module/zookeeper-3.5.7/zkData
1 |
|
注意这里还需要配置每个myid文件 写明对应的id
1 | 且在vim zoo.cfg |